本文档是对Vulkan Tutorial教程的翻译,非官方翻译,仅供vulkan爱好者参考学习。如果有翻译错误,请留言指出,或者联系占航(hangliebe@163.com)进行修正,感谢。建议英文好的朋友直接读原文档。
关注我的微博主页
2022-02-20 v1.0
顶点缓冲区
顶点输入描述
简介
在接下来的几章中,我们将用内存中的顶点缓冲区取代顶点着色器中的硬编码顶点数据。我们将从最简单的方法开始,即创建一个CPU可见的缓冲区,并使用memcpy将顶点数据直接复制到其中,之后我们将看到如何使用一个暂存缓冲区将顶点数据复制到高性能的内存。
顶点着色器
首先改变顶点着色器,使其不再将顶点数据纳入着色器代码本身。顶点着色器使用
in 关键字从顶点缓冲区获取输入。
#version 450
layout(location = 0) in vec2 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}inPosition和inColor变量是顶点属性。它们是在顶点缓冲区中每个顶点指定的属性,就像我们使用两个数组手动指定每个顶点的位置和颜色一样。请确保重新编译顶点着色器!
就像 fragColor一样,layout(location = x)
注解为输入分配的索引,我们以后可以用它来引用它们。重要的是要知道一些类型,如dvec364位矢量,使用多个slots。这意味着它后面的索引必须至少高2个。
layout(location = 0) in dvec3 inPosition;
layout(location = 2) in vec3 inColor;你可以在OpenGL wiki中找到更多关于布局限定符的信息。
顶点数据
我们将顶点数据从着色器代码移动到程序代码中的数组。首先包括 GLM 库,它为我们提供了与线性代数相关的类型,如向量和矩阵。我们将使用这些类型来指定位置和颜色向量。
#include <glm/glm.hpp>创建一个名为Vertex的新结构,其中包含我们将在其中的顶点着色器中使用的两个属性:
struct Vertex {
glm::vec2 pos;
glm::vec3 color;
};GLM 方便地为我们提供了与着色器语言中使用的向量类型完全匹配的 C++ 类型。
const std::vector<Vertex> vertices = {
{{0.0f, -0.5f}, {1.0f, 0.0f, 0.0f}},
{{0.5f, 0.5f}, {0.0f, 1.0f, 0.0f}},
{{-0.5f, 0.5f}, {0.0f, 0.0f, 1.0f}}
};现在使用 Vertex
结构来指定一个顶点数据数组。我们使用与以前完全相同的位置和颜色值,但现在它们被组合成一个顶点数组。这称为
interleaving 顶点属性。
绑定描述
下一步是告诉Vulkan,一旦这个数据格式被上传到GPU内存,如何将其传递给顶点着色器。有两种类型的结构需要用来传达这一信息。
第一个结构是VkVertexInputBindingDescription,我们将在Vertex结构中添加一个成员函数,将正确的数据填充到其中。
struct Vertex {
glm::vec2 pos;
glm::vec3 color;
static VkVertexInputBindingDescription getBindingDescription() {
VkVertexInputBindingDescription bindingDescription{};
return bindingDescription;
}
};顶点绑定描述了以何种速度从内存中加载整个顶点的数据。它指定了数据项之间的字节数,以及是否在每个顶点之后或每个实例之后移动到下一个数据项。
VkVertexInputBindingDescription bindingDescription{};
bindingDescription.binding = 0;
bindingDescription.stride = sizeof(Vertex);
bindingDescription.inputRate = VK_VERTEX_INPUT_RATE_VERTEX;我们所有的每个顶点数据都集中在一个数组中,所以我们只需要一个绑定。绑定 “参数指定了绑定数组中绑定的索引。stride”参数指定了从一个条目到下一个条目的字节数,“inputRate”参数可以有以下值之一。
vk_vertex_input_rate_vertex: 在每个顶点之后移动到下一个数据条目vk_vertex_input_rate_instance: 移动到每个实例后的下一个数据项
我们不打算使用实例渲染,所以我们将坚持使用每个顶点的数据。
属性描述
第二个描述如何处理顶点输入的结构是VkVertexInputAttributeDescription。我们将在Vertex中添加另一个辅助函数来填充这些结构。
#include <array>
...
static std::array<VkVertexInputAttributeDescription, 2> getAttributeDescriptions() {
std::array<VkVertexInputAttributeDescription, 2> attributeDescriptions{};
return attributeDescriptions;
}正如函数原型所示,将有两个这样的结构。一个属性描述结构描述了如何从来自绑定描述的顶点数据块中提取顶点属性。我们有两个属性,位置和颜色,所以我们需要两个属性描述结构。
attributeDescriptions[0].binding = 0;
attributeDescriptions[0].location = 0;
attributeDescriptions[0].format = VK_FORMAT_R32G32_SFLOAT;
attributeDescriptions[0].offset = offsetof(Vertex, pos);binding
参数告诉Vulkan每个顶点数据来自哪个绑定。location参数引用顶点着色器中输入的location指令。顶点着色器中位置为0的输入是位置,它有两个32位浮点成分。
format参数描述了属性的数据类型。有点令人困惑的是,格式是用与颜色格式相同的枚举法来指定的。以下着色器类型和格式通常一起使用。
float:VK_FORMAT_R32_SFLOATvec2:VK_FORMAT_R32G32_SFLOATvec3:VK_FORMAT_R32G32B32_SFLOATvec4:VK_FORMAT_R32G32B32A32_SFLOAT
正如你所看到的,你应该使用颜色通道的数量与着色器数据类型中的组件数量相匹配的格式。允许使用比着色器中的组件数量更多的通道,但它们将被默默地丢弃。如果通道数低于组件数,那么BGA组件将使用默认值(0,0,1)。颜色类型(SFLOAT,UINT,SINT)和位宽也应该与着色器输入的类型相匹配。请看下面的例子。
ivec2:VK_FORMAT_R32G32_SINT, 一个32位有符号整数的2分量向量uvec4:VK_FORMAT_R32G32B32A32_UINT, 一个由32位无符号整数组成的4分量向量。double:VK_FORMAT_R64_SFLOAT, 一个双精度(64位)浮点数
format参数隐含地定义了属性数据的字节大小,offset参数指定了从每个顶点的数据开始读取的字节数。绑定每次加载一个顶点,位置属性(pos)在这个结构的开始处的偏移量为0字节。这是用
offsetof 宏自动计算的。
attributeDescriptions[1].binding = 0;
attributeDescriptions[1].location = 1;
attributeDescriptions[1].format = VK_FORMAT_R32G32B32_SFLOAT;
attributeDescriptions[1].offset = offsetof(Vertex, color);颜色属性的描述方式大致相同。
管道顶点输入
我们现在需要设置图形管道,通过引用createGraphicsPipeline中的结构来接受这种格式的顶点数据。找到vertexInputInfo结构并修改它以引用两个描述:
auto bindingDescription = Vertex::getBindingDescription();
auto attributeDescriptions = Vertex::getAttributeDescriptions();
vertexInputInfo.vertexBindingDescriptionCount = 1;
vertexInputInfo.vertexAttributeDescriptionCount = static_cast<uint32_t>(attributeDescriptions.size());
vertexInputInfo.pVertexBindingDescriptions = &bindingDescription;
vertexInputInfo.pVertexAttributeDescriptions = attributeDescriptions.data();管道现在已经准备好接受vertices容器格式的顶点数据,并将其传递给我们的顶点着色器。如果你现在在启用验证层的情况下运行程序,你会看到它抱怨说没有与绑定的顶点缓冲器。下一步是创建一个顶点缓冲区,并将顶点数据移至其中,以便GPU能够访问它。
C++ code / Vertex shader / Fragment shader
创建顶点缓冲区
简介
Vulkan中的缓冲区是用于存储任意数据的内存区域,可以由显卡读取。它们可以用来存储顶点数据,我们将在本章中这样做,但它们也可以用于许多其他用途,我们将在未来的章节中探讨。与我们迄今为止一直在处理的Vulkan对象不同,缓冲区不会自动为自己分配内存。前面几章的工作表明,Vulkan API让程序员控制了几乎所有的东西,而内存管理就是其中之一。
创建Buffer
创建一个新函数 createVertexBuffer 并在
createCommandBuffers 之前从 initVulkan
调用它。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createVertexBuffer();
createCommandBuffers();
createSyncObjects();
}
...
void createVertexBuffer() {
}创建缓冲区需要我们填充 VkBufferCreateInfo
结构。
VkBufferCreateInfo bufferInfo{};
bufferInfo.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
bufferInfo.size = sizeof(vertices[0]) * vertices.size();该结构的第一个字段是size,它指定了缓冲区的字节大小。使用sizeof可以直接计算出顶点数据的字节大小。
bufferInfo.usage = VK_BUFFER_USAGE_VERTEX_BUFFER_BIT;第二个字段是
usage,它表示缓冲区中的数据将用于哪些目的。可以用位法或指定多个用途。我们的用例是一个顶点缓冲区,我们将在以后的章节中研究其他类型的用途。
bufferInfo.sharingMode = VK_SHARING_MODE_EXCLUSIVE;就像交换链中的图像一样,缓冲区也可以被一个特定的队列家族所拥有,或者同时在多个之间共享。缓冲区将只从图形队列中使用,所以我们可以坚持独占访问。
flags参数用于配置稀疏缓冲区内存,现在并不相关。我们将它保留在默认值
0。
我们现在可以用vkCreateBuffer创建缓冲区。定义一个类成员来保存缓冲区句柄,并将其称为vertexBuffer。
VkBuffer vertexBuffer;
...
void createVertexBuffer() {
VkBufferCreateInfo bufferInfo{};
bufferInfo.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
bufferInfo.size = sizeof(vertices[0]) * vertices.size();
bufferInfo.usage = VK_BUFFER_USAGE_VERTEX_BUFFER_BIT;
bufferInfo.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
if (vkCreateBuffer(device, &bufferInfo, nullptr, &vertexBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to create vertex buffer!");
}
}缓冲区应该可以在渲染命令中使用,直到程序结束,而且它不依赖于交换链,所以我们将在原来的cleanup函数中清理它。
void cleanup() {
cleanupSwapChain();
vkDestroyBuffer(device, vertexBuffer, nullptr);
...
}内存需求
缓冲区已经被创建,但实际上还没有分配到任何内存。为缓冲区分配内存的第一步是使用命名恰当的vkGetBufferMemoryRequirements函数查询其内存需求。
VkMemoryRequirements memRequirements;
vkGetBufferMemoryRequirements(device, vertexBuffer, &memRequirements);VkMemoryRequirements
结构有三个字段。
size: 所需内存量的大小,以字节为单位,可能与`bufferInfo.size’不同。alignment: 缓冲区在分配的内存区域中开始的偏移,以字节为单位,取决于bufferInfo.usage和bufferInfo.flags。memoryTypeBits。适合缓冲区的内存类型的位域。
图形卡可以提供不同类型的内存来进行分配。每种类型的内存在允许的操作和性能特征方面都有所不同。我们需要结合缓冲区的要求和我们自己的应用要求来找到合适的内存类型来使用。让我们为这个目的创建一个新的函数findMemoryType。
uint32_t findMemoryType(uint32_t typeFilter, VkMemoryPropertyFlags properties) {
}首先我们需要使用vkGetPhysicalDeviceMemoryProperties查询可用的内存类型信息。
VkPhysicalDeviceMemoryProperties memProperties;
vkGetPhysicalDeviceMemoryProperties(physicalDevice, &memProperties);VkPhysicalDeviceMemoryProperties
结构有两个数组memoryTypes和memoryHeaps。内存堆是不同的内存资源,如专用的VRAM和RAM中的交换空间,以便在VRAM耗尽时使用。不同类型的内存存在于这些堆中。现在我们只关心内存的类型,而不是它来自哪个堆,但你可以想象这可能会影响性能。
让我们首先找到一个适合缓冲区本身的内存类型:
for (uint32_t i = 0; i < memProperties.memoryTypeCount; i++) {
if (typeFilter & (1 << i)) {
return i;
}
}
throw std::runtime_error("failed to find suitable memory type!");typeFilter参数将被用来指定适合的内存类型的位域。这意味着我们可以通过简单的迭代找到合适的内存类型的索引,并检查相应的位是否被设置为1。
然而,我们不只是对适合顶点缓冲区的内存类型感兴趣。我们还需要能够将我们的顶点数据写入该内存中。memoryTypes数组由VkMemoryType结构组成,指定每种类型的内存的堆和属性。属性定义了内存的特殊功能,比如能够映射它,这样我们就可以从CPU写到它。这个属性用VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT表示,但我们也需要使用VK_MEMORY_PROPERTY_HOST_COHERENT_BIT属性。我们将在映射内存时看到原因。
现在我们可以修改循环,以检查对该属性的支持情况:
for (uint32_t i = 0; i < memProperties.memoryTypeCount; i++) {
if ((typeFilter & (1 << i)) && (memProperties.memoryTypes[i].propertyFlags & properties) == properties) {
return i;
}
}我们可能有不止一个理想的属性,所以我们应该检查位和的结果是否不只是非零,而是等于理想属性的位域。如果有一个适合缓冲区的内存类型,并且也有我们需要的所有属性,那么我们就返回它的索引,否则就抛出一个异常。
内存分配
我们现在有办法确定正确的内存类型,所以我们可以通过填写VkMemoryAllocateInfo结构实际分配内存。
VkMemoryAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
allocInfo.allocationSize = memRequirements.size;
allocInfo.memoryTypeIndex = findMemoryType(memRequirements.memoryTypeBits, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT);现在,内存分配就像指定大小和类型一样简单,这两者都来自顶点缓冲区的内存需求和所需的属性。创建一个类成员来存储内存的句柄,并用vkAllocateMemory来分配它。
VkBuffer vertexBuffer;
VkDeviceMemory vertexBufferMemory;
...
if (vkAllocateMemory(device, &allocInfo, nullptr, &vertexBufferMemory) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate vertex buffer memory!");
}如果内存分配成功,那么我们现在可以使用vkBBufferMemory将该内存与缓冲区联系起来:
vkBindBufferMemory(device, vertexBuffer, vertexBufferMemory, 0);前三个参数是不言自明的,第四个参数是内存区域的偏移量。由于这块内存是专门为顶点缓冲区分配的,所以偏移量就是0'。如果偏移量不为零,那么就要求它能被memRequirements.alignment`整除。
当然,就像C++中的动态内存分配一样,内存应该在某个时刻被释放。绑定在缓冲区对象上的内存,一旦缓冲区不再被使用,就可能被释放,所以让我们在缓冲区被销毁后释放它:
void cleanup() {
cleanupSwapChain();
vkDestroyBuffer(device, vertexBuffer, nullptr);
vkFreeMemory(device, vertexBufferMemory, nullptr);填充顶点数据
现在是把顶点数据复制到缓冲区的时候了。这是通过使用vkMapMemory映射缓冲区内存到CPU可访问的内存来完成的。
void* data;
vkMapMemory(device, vertexBufferMemory, 0, bufferInfo.size, 0, &data);这个函数允许我们访问由偏移量和大小定义的指定内存资源的一个区域。这里的偏移量和大小分别是0和bufferInfo.size。也可以指定特殊值VK_WHOLE_SIZE来映射所有的内存。倒数第二个参数可以用来指定标志,但目前的API中还没有任何可用的标志。它必须被设置为`0’值。最后一个参数指定指向映射内存的指针的输出。
void* data;
vkMapMemory(device, vertexBufferMemory, 0, bufferInfo.size, 0, &data);
memcpy(data, vertices.data(), (size_t) bufferInfo.size);
vkUnmapMemory(device, vertexBufferMemory);现在你可以简单地将顶点数据memcpy到映射的内存中,然后使用vkUnmapMemory再次取消映射。不幸的是,驱动程序可能不会立即将数据复制到缓冲区内存中,例如,由于缓存的原因。也有可能写到缓冲区的数据在映射的内存中还不可见。有两种方法来处理这个问题。
- 使用主机一致性的内存堆,用
VK_MEMORY_PROPERTY_HOST_COHERENT_BIT表示 - 在写入映射的内存后调用
vkFlushMappedMemoryRanges,并在从映射的内存读取前调用vkInvalidateMappedMemoryRanges
我们选择了第一种方法,它可以确保映射的内存总是与分配的内存内容相匹配。请记住,这可能会导致性能比显式刷新稍差,但我们将在下一章看到为什么这并不重要。
冲洗内存范围或使用连贯的内存堆意味着驱动程序将意识到我们对缓冲区的写入,但这并不意味着它们在GPU上实际可见。向GPU传输数据是一个发生在后台的操作,规范只是告诉我们,保证在下一次调用vkQueueSubmit时完成。
绑定顶点缓存区
现在剩下的就是在渲染操作中绑定顶点缓冲区。我们将扩展recordCommandBuffer函数来完成这个任务。
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);
VkBuffer vertexBuffers[] = {vertexBuffer};
VkDeviceSize offsets[] = {0};
vkCmdBindVertexBuffers(commandBuffer, 0, 1, vertexBuffers, offsets);
vkCmdDraw(commandBuffer, static_cast<uint32_t>(vertices.size()), 1, 0, 0);vkCmdBindVertexBuffers函数用于将顶点缓冲区绑定到绑定上,就像我们在上一章设置的绑定。前两个参数,除了命令缓冲区,还指定了我们要指定顶点缓冲区的偏移量和绑定数量。最后两个参数指定要绑定的顶点缓冲区阵列和开始读取顶点数据的字节偏移。你还应该改变对vkCmdDraw的调用,以传递缓冲区中的顶点数量,而不是硬编码的数字3。
现在运行该程序,你应该再次看到熟悉的三角形:
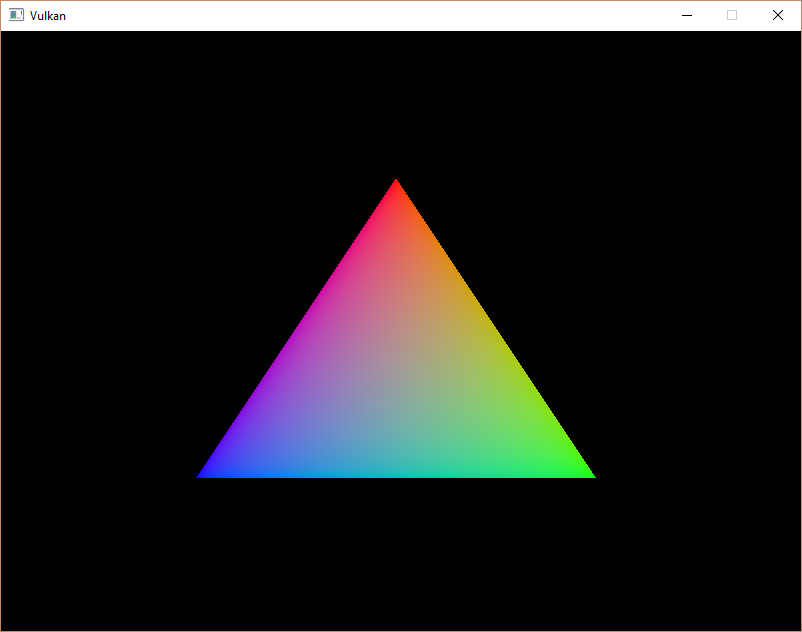
试着通过修改vertices数组将顶部顶点的颜色改为白色:
const std::vector<Vertex> vertices = {
{{0.0f, -0.5f}, {1.0f, 1.0f, 1.0f}},
{{0.5f, 0.5f}, {0.0f, 1.0f, 0.0f}},
{{-0.5f, 0.5f}, {0.0f, 0.0f, 1.0f}}
};再次运行该程序,你应该看到以下内容: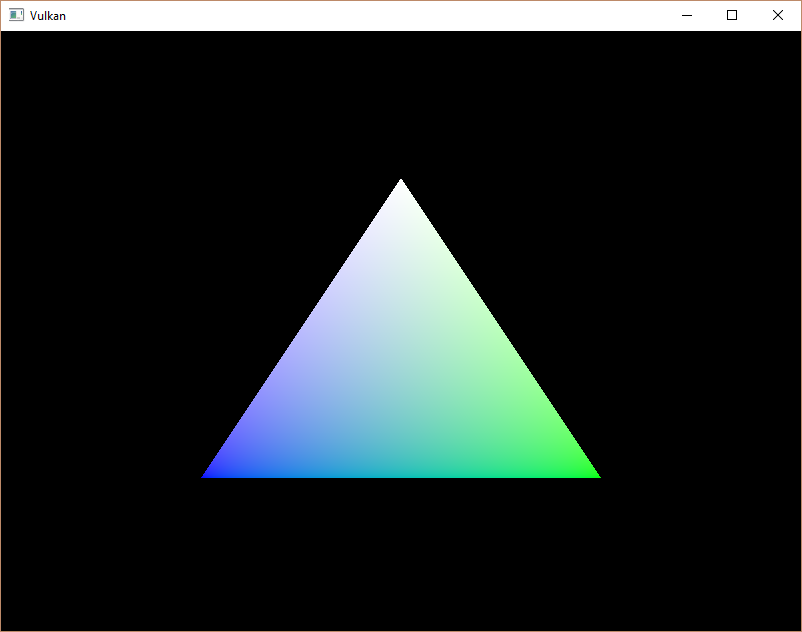
在下一章中,我们将看一下将顶点数据复制到顶点缓冲区的不同方法,它能带来更好的性能,但需要更多的工作。
C++ code / Vertex shader / Fragment shader
暂存缓冲区
简介
我们现在拥有的顶点缓冲区工作正常,但允许我们从 CPU
访问它的内存类型可能不是显卡本身读取的最佳内存类型。最佳内存具有
VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT 标志,专用显卡上的 CPU
通常无法访问。在本章中,我们将创建两个顶点缓冲区。 CPU
可访问内存中的一个暂存缓冲区,用于将数据从顶点数组上传到,最后一个顶点缓冲区位于设备本地内存中。然后,我们将使用缓冲区复制命令将数据从暂存缓冲区移动到实际的顶点缓冲区。
传输队列
缓冲区复制命令需要一个支持传输操作的队列族,使用
VK_QUEUE_TRANSFER_BIT 表示。好消息是任何具有
VK_QUEUE_GRAPHICS_BIT 或 VK_QUEUE_COMPUTE_BIT
能力的队列族已经隐式支持 VK_QUEUE_TRANSFER_BIT
操作。在这些情况下,实现不需要在 queueFlags
中明确列出它。
如果您喜欢挑战,那么您仍然可以尝试使用不同的队列族专门用于传输操作。它将要求您对程序进行以下修改:
- 修改
QueueFamilyIndices和findQueueFamilies以显式查找具有VK_QUEUE_TRANSFER_BIT位的队列族,而不是VK_QUEUE_GRAPHICS_BIT。 - 修改
createLogicalDevice以请求传输队列的句柄 - 为在传输队列系列上提交的命令缓冲区创建第二个命令池
- 将资源的
sharingMode更改为VK_SHARING_MODE_CONCURRENT并指定图形和传输队列系列 - 提交任何传输命令,如
vkCmdCopyBuffer(我们将在本章中使用)传输队列而不是图形队列
这有点工作,但它会教你很多关于如何在队列族之间共享资源的知识。
创建抽象缓冲区
因为我们将在本章中创建多个缓冲区,所以将缓冲区创建移至辅助函数是一个好主意。创建一个新函数
createBuffer 并将 createVertexBuffer
中的代码(映射除外)移动到它。
void createBuffer(VkDeviceSize size, VkBufferUsageFlags usage, VkMemoryPropertyFlags properties, VkBuffer& buffer, VkDeviceMemory& bufferMemory) {
VkBufferCreateInfo bufferInfo{};
bufferInfo.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
bufferInfo.size = size;
bufferInfo.usage = usage;
bufferInfo.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
if (vkCreateBuffer(device, &bufferInfo, nullptr, &buffer) != VK_SUCCESS) {
throw std::runtime_error("failed to create buffer!");
}
VkMemoryRequirements memRequirements;
vkGetBufferMemoryRequirements(device, buffer, &memRequirements);
VkMemoryAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
allocInfo.allocationSize = memRequirements.size;
allocInfo.memoryTypeIndex = findMemoryType(memRequirements.memoryTypeBits, properties);
if (vkAllocateMemory(device, &allocInfo, nullptr, &bufferMemory) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate buffer memory!");
}
vkBindBufferMemory(device, buffer, bufferMemory, 0);
}确保为缓冲区大小、内存属性和使用添加参数,以便我们可以使用此函数创建许多不同类型的缓冲区。最后两个参数是要写入句柄的输出变量。
您现在可以从 createVertexBuffer
中删除缓冲区创建和内存分配代码,而只需调用 createBuffer
代替:
void createVertexBuffer() {
VkDeviceSize bufferSize = sizeof(vertices[0]) * vertices.size();
createBuffer(bufferSize, VK_BUFFER_USAGE_VERTEX_BUFFER_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, vertexBuffer, vertexBufferMemory);
void* data;
vkMapMemory(device, vertexBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, vertices.data(), (size_t) bufferSize);
vkUnmapMemory(device, vertexBufferMemory);
}运行你的程序以确保顶点缓冲区仍然正常工作。
使用一个暂存缓冲区
我们现在要改变createVertexBuffer,只使用主机可见缓冲区作为临时缓冲区,使用设备本地缓冲区作为实际的顶点缓冲区。
void createVertexBuffer() {
VkDeviceSize bufferSize = sizeof(vertices[0]) * vertices.size();
VkBuffer stagingBuffer;
VkDeviceMemory stagingBufferMemory;
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_SRC_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, stagingBuffer, stagingBufferMemory);
void* data;
vkMapMemory(device, stagingBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, vertices.data(), (size_t) bufferSize);
vkUnmapMemory(device, stagingBufferMemory);
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_DST_BIT | VK_BUFFER_USAGE_VERTEX_BUFFER_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, vertexBuffer, vertexBufferMemory);
}我们现在使用新的 stagingBuffer 和
stagingBufferMemory
来映射和复制顶点数据。在本章中,我们将使用两个新的缓冲区使用标志:
VK_BUFFER_USAGE_TRANSFER_SRC_BIT:缓冲区可以用作内存传输操作中的源。VK_BUFFER_USAGE_TRANSFER_DST_BIT:缓冲区可以用作内存传输操作中的目标。
vertexBuffer
现在是从设备本地的内存类型分配的,这通常意味着我们无法使用 vkMapMemory。但是,我们可以将数据从stagingBuffer复制到vertexBuffer。我们必须通过指定
stagingBuffer 的传输源标志和 vertexBuffer
的传输目标标志以及顶点缓冲区使用标志来表明我们打算这样做。
我们现在要编写一个函数来将内容从一个缓冲区复制到另一个缓冲区,称为copyBuffer。
void copyBuffer(VkBuffer srcBuffer, VkBuffer dstBuffer, VkDeviceSize size) {
}内存传输操作使用命令缓冲区执行,就像绘图命令一样。因此我们必须首先分配一个临时命令缓冲区。您可能希望为这些类型的短期缓冲区创建一个单独的命令池,因为实现可能能够应用内存分配优化。在这种情况下,您应该在命令池生成期间使用
VK_COMMAND_POOL_CREATE_TRANSIENT_BIT 标志。
void copyBuffer(VkBuffer srcBuffer, VkBuffer dstBuffer, VkDeviceSize size) {
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
allocInfo.commandPool = commandPool;
allocInfo.commandBufferCount = 1;
VkCommandBuffer commandBuffer;
vkAllocateCommandBuffers(device, &allocInfo, &commandBuffer);
}并立即开始记录命令缓冲区:
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
vkBeginCommandBuffer(commandBuffer, &beginInfo);我们将只使用一次命令缓冲区并等待从函数返回,直到复制操作完成执行。使用
VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT
告诉驱动程序我们的意图是一个很好的做法。
VkBufferCopy copyRegion{};
copyRegion.srcOffset = 0; // Optional
copyRegion.dstOffset = 0; // Optional
copyRegion.size = size;
vkCmdCopyBuffer(commandBuffer, srcBuffer, dstBuffer, 1, ©Region);缓冲区的内容使用 vkCmdCopyBuffer
命令传输。它将源缓冲区和目标缓冲区作为参数,以及要复制的区域数组。这些区域在
VkBufferCopy
结构中定义,由源缓冲区偏移量、目标缓冲区偏移量和尺寸。与 vkMapMemory
命令不同,此处无法指定 VK_WHOLE_SIZE。
vkEndCommandBuffer(commandBuffer);该命令缓冲区仅包含复制命令,因此我们可以在此之后立即停止记录。现在执行命令缓冲区以完成传输:
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffer;
vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE);
vkQueueWaitIdle(graphicsQueue);与绘制命令不同的是,这次没有我们需要等待的事件。我们只是想立即执行缓冲区的传输。又有两种可能的方法来等待这个转移的完成。我们可以使用栅栏,用vkWaitForFences等待,或者简单地用vkQueueWaitIdle等待传输队列的空闲。栅栏将允许你同时安排多个传输,并等待它们全部完成,而不是一次执行一个。这可能会给驱动更多的机会来优化。
vkFreeCommandBuffers(device, commandPool, 1, &commandBuffer);不要忘记清理用于传输操作的命令缓冲区。
我们现在可以从createVertexBuffer函数中调用copyBuffer来将顶点数据转移到设备本地缓冲区:
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_DST_BIT | VK_BUFFER_USAGE_VERTEX_BUFFER_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, vertexBuffer, vertexBufferMemory);
copyBuffer(stagingBuffer, vertexBuffer, bufferSize);将数据从暂存缓冲区复制到设备缓冲区后,我们应该对其进行清理:
...
copyBuffer(stagingBuffer, vertexBuffer, bufferSize);
vkDestroyBuffer(device, stagingBuffer, nullptr);
vkFreeMemory(device, stagingBufferMemory, nullptr);
}运行你的程序来验证你是否又看到了熟悉的三角形。现在可能看不到改进,但它的顶点数据现在正从高性能内存中加载。当我们要开始渲染更复杂的几何体时,这就很重要了。
结论
应该注意的是,在现实世界的应用程序中,您不应该实际调用 vkAllocateMemory
对于每个单独的缓冲区。同时内存分配的最大数量受到maxMemoryAllocationCount物理设备限制的限制,即使在
NVIDIA GTX 1080
等高端硬件上也可能低至4096。为大量对象分配内存的正确方法同时是创建一个自定义分配器,通过使用我们在许多函数中看到的
offset 参数在许多不同对象之间拆分单个分配。
您可以自己实现这样的分配器,也可以使用 GPUOpen 倡议提供的 VulkanMemoryAllocator 库。但是,对于本教程,可以为每个资源使用单独的分配,因为我们现在不会接近达到任何这些限制。
C++ code / Vertex shader / Fragment shader
索引缓冲区
介绍
在现实世界的应用中,你要渲染的三维网格往往会在多个三角形之间共享顶点。即使是画一个简单的矩形,也已经发生了这种情况。

绘制一个矩形需要两个三角形,这意味着我们需要一个有6个顶点的顶点缓冲器。问题是,两个顶点的数据需要重复,导致50%的冗余。这在更复杂的网格中只会变得更糟,顶点在平均3个三角形中被重复使用。解决这个问题的方法是使用索引缓冲区。
索引缓冲区本质上是一个进入顶点缓冲区的指针阵列。它允许你重新排列顶点数据,并为多个顶点重复使用现有的数据。上面的插图展示了如果我们有一个包含四个独特顶点的顶点缓冲区,那么矩形的索引缓冲区会是什么样子。前三个索引定义了右上角的三角形,后三个索引定义了左下角的三角形的顶点。
创建索引缓冲区
在本章中,我们将修改顶点数据并添加索引数据,以绘制一个像图中那样的矩形。修改顶点数据以表示四个角:
const std::vector<Vertex> vertices = {
{{-0.5f, -0.5f}, {1.0f, 0.0f, 0.0f}},
{{0.5f, -0.5f}, {0.0f, 1.0f, 0.0f}},
{{0.5f, 0.5f}, {0.0f, 0.0f, 1.0f}},
{{-0.5f, 0.5f}, {1.0f, 1.0f, 1.0f}}
};左上角是红色,右上角是绿色,右下角是蓝色,左下角是白色。我们将添加一个新的数组indices来表示索引缓冲区的内容。它应该与插图中的索引相匹配,以绘制右上角的三角形和左下角的三角形。
const std::vector<uint16_t> indices = {
0, 1, 2, 2, 3, 0
};可以使用uint16_t或uint32_t作为你的索引缓冲区,这取决于vertices中的条目数量。我们现在可以坚持使用uint16_t,因为我们使用的是少于65535个唯一的顶点。
就像顶点数据一样,索引需要被上传到一个VkBuffer,以便GPU能够访问它们。定义两个新的类成员来保存索引缓冲区的资源:
VkBuffer vertexBuffer;
VkDeviceMemory vertexBufferMemory;
VkBuffer indexBuffer;
VkDeviceMemory indexBufferMemory;我们现在要添加的createIndexBuffer函数与createVertexBuffer几乎相同:
void initVulkan() {
...
createVertexBuffer();
createIndexBuffer();
...
}
void createIndexBuffer() {
VkDeviceSize bufferSize = sizeof(indices[0]) * indices.size();
VkBuffer stagingBuffer;
VkDeviceMemory stagingBufferMemory;
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_SRC_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, stagingBuffer, stagingBufferMemory);
void* data;
vkMapMemory(device, stagingBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, indices.data(), (size_t) bufferSize);
vkUnmapMemory(device, stagingBufferMemory);
createBuffer(bufferSize, VK_BUFFER_USAGE_TRANSFER_DST_BIT | VK_BUFFER_USAGE_INDEX_BUFFER_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, indexBuffer, indexBufferMemory);
copyBuffer(stagingBuffer, indexBuffer, bufferSize);
vkDestroyBuffer(device, stagingBuffer, nullptr);
vkFreeMemory(device, stagingBufferMemory, nullptr);
}只有两个明显的区别。bufferSize现在等于索引的数量乘以索引类型的大小,可以是uint16_t或uint32_t。indexBuffer的用法应该是VK_BUFFER_USAGE_INDEX_BUFFER_BIT而不是VK_BUFFER_USAGE_VERTEX_BUFFER_BIT,这是有道理的。除此之外,过程是完全一样的。我们创建一个暂存缓冲区来复制indices的内容,然后将其复制到最终设备的本地索引缓冲区。
索引缓冲区应该在程序结束时被清理掉,就像顶点缓冲区一样:
void cleanup() {
cleanupSwapChain();
vkDestroyBuffer(device, indexBuffer, nullptr);
vkFreeMemory(device, indexBufferMemory, nullptr);
vkDestroyBuffer(device, vertexBuffer, nullptr);
vkFreeMemory(device, vertexBufferMemory, nullptr);
...
}使用一个索引缓冲区
使用索引缓冲区进行绘图涉及到对createCommandBuffers的两个改变。我们首先需要绑定索引缓冲区,就像我们为顶点缓冲区做的那样。不同的是,你只能有一个索引缓冲区。不幸的是,不可能为每个顶点属性使用不同的索引,所以即使只有一个属性有变化,我们确实还是要完全重复顶点数据。
vkCmdBindVertexBuffers(commandBuffers[i], 0, 1, vertexBuffers, offsets);
vkCmdBindIndexBuffer(commandBuffers[i], indexBuffer, 0, VK_INDEX_TYPE_UINT16);用vkCmdBindIndexBuffer绑定一个索引缓冲区,它有索引缓冲区、其中的字节偏移和索引数据的类型作为参数。如前所述,可能的类型是VK_INDEX_TYPE_UINT16和VK_INDEX_TYPE_UINT32。
仅仅绑定一个索引缓冲区还不能改变什么,我们还需要改变绘图命令来告诉Vulkan使用索引缓冲区。删除vkCmdDraw一行,用vkCmdDrawIndexed取代:
vkCmdDrawIndexed(commandBuffers[i], static_cast<uint32_t>(indices.size()), 1, 0, 0, 0);对这个函数的调用与vkCmdDraw非常相似。前两个参数指定索引的数量和实例的数量。我们不使用实例化,所以只指定1实例。索引数代表将被传递到顶点缓冲器的顶点数量。下一个参数指定索引缓冲区的偏移量,使用1的值将导致显卡从第二个索引开始读取。倒数第二个参数指定了一个偏移量,以添加到索引缓冲区的索引中。最后一个参数指定了一个用于实例化的偏移量,我们不使用这个参数。
现在运行你的程序,你应该看到以下内容。
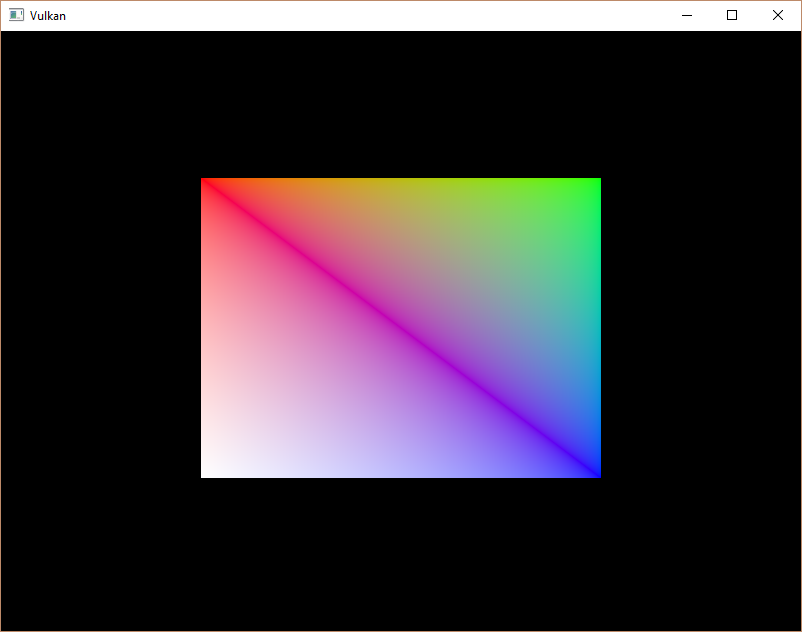
你现在知道了如何通过重复使用带有索引缓冲区的顶点来节省内存。这在未来的一章中会变得特别重要,因为我们要加载复杂的三维模型。
上一章已经提到,你应该从一个内存分配中分配多个资源,如缓冲区,但事实上你应该更进一步。驱动程序开发人员建议,你也可以将多个缓冲区,比如顶点和索引缓冲区,存储到一个VkBuffer中,并在vkCmdBindVertexBuffers等命令中使用偏移量。这样做的好处是,你的数据在这种情况下更容易被缓存,因为它们之间的距离更近。如果在同一渲染操作中不使用多个资源,甚至可以为它们重用同一块内存,当然,前提是它们的数据被刷新了。这被称为aliasing,一些Vulkan函数有明确的标志来指定你要做这个。
留言板