本文档是对Vulkan Tutorial教程的翻译,非官方翻译,仅供vulkan爱好者参考学习。如果有翻译错误,请留言指出,或者联系占航(hangliebe@163.com)进行修正,感谢。建议英文好的朋友直接读原文档。
关注我的微博主页
2022-02-20 v1.0
画一个三角形
开始
基本代码
总体结构
在上一章中,你已经创建了一个具有所有适当配置的Vulkan项目,并使用示例代码对其进行了测试。在这一章中,我们将从头开始编写以下代码:
#include <vulkan/vulkan.h>
#include <iostream>
#include <stdexcept>
#include <cstdlib>
class HelloTriangleApplication {
public:
void run() {
initVulkan();
mainLoop();
cleanup();
}
private:
void initVulkan() {
}
void mainLoop() {
}
void cleanup() {
}
};
int main() {
HelloTriangleApplication app;
try {
app.run();
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}我们首先包括LunarG
SDK的Vulkan头,它提供了函数、结构和枚举。stdexcept'和iostream’头文件被包括在内,用于报告和传播错误。cstdlib头提供了EXIT_SUCCESS和EXIT_FAILURE宏。
程序本身被包装成一个类,我们将把Vulkan对象存储为私有类成员,并添加函数来启动每个对象,这些函数将被initVulkan函数调用。一旦一切准备就绪,我们将进入主循环,开始渲染帧。我们将填入mainLoop函数,以包括一个循环,该循环一直迭代到一会儿关闭窗口。一旦窗口关闭,mainLoop返回,我们将确保取消分配我们在cleanup函数中使用的资源。
如果在执行过程中发生任何致命的错误,我们将抛出一个std::runtime_error异常,并附上描述性的信息,该信息将传播到main函数,并打印到命令提示符上。为了处理各种标准的异常类型,我们抓取更多的`std::exception’。我们将很快处理的一个错误的例子是发现某个必要的扩展不被支持。
在这一章之后的每一章都会增加一个新的函数,该函数将从initVulkan中调用,并在cleanup中为需要在最后释放的私有类成员增加一个或多个新的Vulkan对象。
资源管理
就像用malloc分配的每块内存都需要调用free一样,我们创建的每个Vulkan对象在不再需要时都需要明确销毁。在C++中,可以使用RAII或``头中提供的智能指针来执行自动资源管理。然而,我选择在本教程中对Vulkan对象的分配和删除进行明确说明。毕竟,Vulkan的利基是明确每一个操作以避免错误,所以明确对象的生命周期对学习API的工作方式是有好处的。
在跟随本教程之后,你可以通过编写在构造函数中获取Vulkan对象并在析构函数中释放它们的C++类来实现自动资源管理,或者根据你的所有权要求,为std::unique_ptr或std::shared_ptr提供一个自定义的删除器。RAII是大型Vulkan程序的推荐模型,但对于学习来说,知道幕后发生了什么总是好的。
Vulkan对象要么用vkCreateXXX这样的函数直接创建,要么通过vkAllocateXXX这样的函数分配给另一个对象。在确保一个对象不再被用于任何地方后,你需要用对应的vkDestroyXXX和vkFreeXXX销毁它。对于不同类型的对象,这些函数的参数通常是不同的,但有一个参数是它们都有的。pAllocator。这是一个可选的参数,允许你指定自定义内存分配器的回调。在本教程中,我们将忽略这个参数,而总是传递nullptr作为参数。
集成GLFW
如果你想将Vulkan用于屏幕外的渲染,那么不创建窗口也能很好地工作,但如果真的能显示一些东西,那就更令人兴奋了
首先将#include行替换为:
#define GLFW_INCLUDE_VULKAN
#include <GLFW/glfw3.h>这样GLFW将包括它自己的定义并自动加载Vulkan头。添加一个initWindow函数,并在其他调用之前从run函数中添加对它的调用。我们将使用该函数来初始化GLFW并创建一个窗口。
void run() {
initWindow();
initVulkan();
mainLoop();
cleanup();
}
private:
void initWindow() {
}在initWindow中的第一个调用应该是glfwInit(),它初始化GLFW库。因为GLFW最初被设计为创建一个OpenGL上下文,我们需要告诉它不要使用下面的调用创建OpenGL上下文:
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);Because handling resized windows takes special care that we’ll look into later, disable it for now with another window hint call:
因为处理调整后的窗口需要特别注意,这点我们将在后面研究,现在用另一个窗口提示的调用禁用它:
glfwWindowHint(GLFW_RESIZABLE, GLFW_FALSE);现在剩下的就是创建实际的窗口了。添加一个GLFWwindow* window;私有类成员来存储对它的引用,并用下面的函数初始化该窗口:
window = glfwCreateWindow(800, 600, "Vulkan", nullptr, nullptr);前三个参数指定窗口的宽度、高度和标题。第四个参数允许你选择性地指定打开窗口的显示器,最后一个参数只与OpenGL有关。
使用常量而不是硬编码的宽度和高度数字是个好主意,因为我们在未来会多次引用这些值。我在
HelloTriangleApplication 类定义的上方添加了以下几行:
const uint32_t WIDTH = 800;
const uint32_t HEIGHT = 600;并将创建窗口的调用改为
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);You should now have a initWindow function that looks
like this:
你现在应该有一个initWindow函数,看起来像这样。
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
glfwWindowHint(GLFW_RESIZABLE, GLFW_FALSE);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
}为了保持应用程序的运行,直到错误发生或窗口关闭,我们需要在mainLoop函数中添加一个事件循环,如下所示。
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
}
}这段代码应该是不言自明的。它循环并检查事件,如按下X按钮,直到窗口被用户关闭。这也是我们稍后将调用一个函数来渲染一个单帧的循环。
一旦窗口被关闭,我们需要通过销毁它和终止GLFW本身来清理资源。这将是我们的第一个cleanup代码:
void cleanup() {
glfwDestroyWindow(window);
glfwTerminate();
}当你现在运行该程序时,你应该看到一个名为 Vulkan
的窗口出现,直到应用程序通过关闭该窗口终止。现在我们有了Vulkan应用程序的骨架,让我们来创建第一个Vulkan对象!
Instance
创建一个instance
你需要做的第一件事是通过创建一个instance来初始化Vulkan库。实例是你的应用程序和Vulkan库之间的连接,创建它需要向驱动指定一些关于你的应用程序的细节。
首先添加一个createInstance'函数并在initVulkan’函数中调用它。
void initVulkan() {
createInstance();
}另外,添加一个数据成员来保存实例的句柄:
private:
VkInstance instance;现在,为了创建一个实例,我们首先要在一个结构中填写关于我们应用程序的一些信息。这些数据在技术上是可有可无的,但它可能会给驱动提供一些有用的信息,以便优化我们的特定应用(例如,因为它使用了具有某些特殊行为的知名图形引擎)。这个结构被称为[VkApplicationInfo](https://www.khronos.org/registry/vulkan/specs/1.0/man/html/VkApplicationInfo.html):
void createInstance() {
VkApplicationInfo appInfo{};
appInfo.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
appInfo.pApplicationName = "Hello Triangle";
appInfo.applicationVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.pEngineName = "No Engine";
appInfo.engineVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.apiVersion = VK_API_VERSION_1_0;
}如前所述,Vulkan中的许多结构需要你在sType成员中明确指定类型。这也是许多具有pNext成员的结构之一,可以指向未来的扩展信息。我们在这里使用值初始化,让它保持为nullptr。
Vulkan中的很多信息都是通过结构体而不是函数参数传递的,我们必须再填入一个结构体,为创建实例提供足够的信息。下一个结构不是可选的,它告诉Vulkan驱动我们要使用哪些全局扩展和验证层。这里的全局意味着它们适用于整个程序,而不是特定的设备,这一点将在接下来的几章中变得清晰。
VkInstanceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;前两个参数是直截了当的。接下来的两层则是指定所需的全局扩展。正如在概述章节中提到的,Vulkan是一个与平台无关的API,这意味着你需要一个扩展来与窗口系统对接。GLFW有一个方便的内置函数,可以返回它所需要的扩展,我们可以将其传递给结构:
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
createInfo.enabledExtensionCount = glfwExtensionCount;
createInfo.ppEnabledExtensionNames = glfwExtensions;该结构的最后两个成员决定启用全局验证层。我们将在下一章中更深入地讨论这些问题,所以现在只需将这些成员留空。
createInfo.enabledLayerCount = 0;我们现在已经指定了Vulkan创建实例所需要的一切,我们最终可以执行vkCreateInstance调用:
VkResult result = vkCreateInstance(&createInfo, nullptr, &instance);正如你所看到的,Vulkan中对象创建函数参数遵循的一般模式是。
- 指向带有创建信息的结构的指针
- 指向自定义分配器回调的指针,在本教程中总是
nullptr。 - 指向存储新对象句柄的变量的指针
如果一切顺利,那么实例的句柄就被存储在VkInstance类成员中。几乎所有的Vulkan函数都会返回一个VkResult类型的值,这个值要么是VK_SUCCESS,要么是一个错误代码。为了检查实例是否被成功创建,我们不需要存储结果,可以直接使用成功值的检查来代替。
if (vkCreateInstance(&createInfo, nullptr, &instance) != VK_SUCCESS) {
throw std::runtime_error("failed to create instance!");
}现在运行程序,确保实例创建成功。
检查扩展支持
如果你看一下vkCreateInstance文档,那么你会看到可能的错误代码之一是VK_ERROR_EXTENSION_NOT_PRESENT。我们可以简单地指定我们需要的扩展,如果错误代码出现就终止。这对于像窗口系统接口这样的基本扩展是有意义的,但如果我们想检查可选功能呢?
为了在创建实例之前检索支持的扩展列表,有一个vkEnumerateInstanceExtensionProperties函数。它需要一个存储扩展数量的变量指针和一个VkExtensionProperties的数组来存储扩展的细节。它还需要一个可选的第一个参数,允许我们通过一个特定的验证层来过滤扩展,我们现在将忽略这个参数。
要分配一个数组来保存扩展的详细信息,我们首先需要知道有多少个。你可以通过将后一个参数留空来请求扩展的数量:
uint32_t extensionCount = 0;
vkEnumerateInstanceExtensionProperties(nullptr, &extensionCount, nullptr);现在分配一个数组来保存扩展的细节(include):
std::vector<VkExtensionProperties> extensions(extensionCount);最后,我们可以查询扩展的详细信息:
vkEnumerateInstanceExtensionProperties(nullptr, &extensionCount, extensions.data());每个VkExtensionProperties结构包含一个扩展的名称和版本。我们可以用一个简单的for循环来列出它们(t是一个缩进的制表符):
std::cout << "available extensions:\n";
for (const auto& extension : extensions) {
std::cout << '\t' << extension.extensionName << '\n';
}如果你想提供一些关于Vulkan支持的细节,你可以在createInstance函数中加入这段代码。作为一个挑战,尝试创建一个函数,检查由glfwGetRequiredInstanceExtensions返回的所有扩展是否包含在支持的扩展列表中。
Cleaning up
VkInstance应该只在程序退出前销毁。它可以在cleanup中用vkDestroyInstance函数销毁。
void cleanup() {
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}vkDestroyInstance函数的参数是直接的。正如前一章提到的,Vulkan中的分配和去分配函数有一个可选的分配器回调,我们将通过传递nullptr来忽略它。我们将在接下来的章节中创建的所有其他Vulkan资源都应该在实例被销毁之前被清理掉。
在继续进行实例创建后更复杂的步骤之前,是时候通过检查validation layers来评估我们的调试选项了。
验证层
什么是验证层?
Vulkan API是围绕最小化驱动开销的理念设计的,这一目标的表现之一就是API中默认的错误检查非常有限。即使是将枚举设置为不正确的值或将空指针传递给所需的参数这样简单的错误通常也不会被明确处理,而会简单地导致崩溃或未定义行为。因为Vulkan要求你对你所做的一切都要非常明确,所以很容易犯很多小错误,比如使用一个新的GPU功能而忘记在逻辑设备创建时请求它。
然而,这并不意味着这些检查不能被添加到API中。Vulkan为此引入了一个被称为验证层的优雅系统。验证层是可选的组件,它与Vulkan函数调用挂钩以应用额外的操作。验证层中的常见操作是。
- 对照规范检查参数值,以发现误用情况
- 跟踪对象的创建和销毁以发现资源泄漏
- 通过跟踪调用来源的线程来检查线程的安全性
- 将每个调用及其参数记录到标准输出中
- 跟踪Vulkan调用以进行分析和回放
下面是一个例子,说明诊断验证层中的函数的实现可以是什么样子:
VkResult vkCreateInstance(
const VkInstanceCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkInstance* instance) {
if (pCreateInfo == nullptr || instance == nullptr) {
log("Null pointer passed to required parameter!");
return VK_ERROR_INITIALIZATION_FAILED;
}
return real_vkCreateInstance(pCreateInfo, pAllocator, instance);
}
这些验证层可以自由堆叠,包括你感兴趣的所有调试功能。你可以简单地在调试构建中启用验证层,而在发布构建中完全禁用它们,这样你就可以获得两全其美的效果了。
Vulkan没有内置任何验证层,但LunarG Vulkan SDK提供了一套不错的验证层,可以检查常见的错误。它们也是完全开源的,所以你可以检查它们检查哪种错误并做出贡献。使用验证层是避免你的应用程序因意外依赖未定义的行为而在不同的驱动上崩溃的最好方法。
只有当验证层被安装到系统上时,才能使用它们。例如,LunarG验证层只适用于安装了Vulkan SDK的电脑。
在Vulkan中以前有两种不同类型的验证层:实例和特定设备。当时的想法是,实例层只检查与全局Vulkan对象(如实例)相关的调用,而特定设备层只检查与特定GPU相关的调用。设备特定层现在已被废弃,这意味着实例验证层适用于所有的Vulkan调用。规范文件仍然建议你在设备级别也启用验证层,以实现兼容性,这也是一些实现所要求的。我们将简单地指定与逻辑设备级别的实例相同的层,这一点我们将在后面看到。
使用验证层
在本节中,我们将看到如何启用Vulkan
SDK提供的标准诊断层。就像扩展一样,验证层需要通过指定其名称来启用。所有有用的标准验证都被捆绑在SDK中的一个层中,这个层被称为VK_LAYER_KHRONOS_validation。
让我们首先在程序中添加两个配置变量,以指定要启用的层和是否启用它们。我选择将这个值建立在程序是否在调试模式下被编译的基础上。NDEBUG宏是C++标准的一部分,意味着
“非调试”。
const uint32_t WIDTH = 800;
const uint32_t HEIGHT = 600;
const std::vector<const char*> validationLayers = {
"VK_LAYER_KHRONOS_validation"
};
#ifdef NDEBUG
const bool enableValidationLayers = false;
#else
const bool enableValidationLayers = true;
#endif我们将添加一个新的函数checkValidationLayerSupport来检查所有请求的图层是否可用。首先使用vkEnumerateInstanceLayerProperties函数列出所有可用的层。它的用法与实例创建章节中讨论过的vkEnumerateInstanceExtensionProperties相同。
bool checkValidationLayerSupport() {
uint32_t layerCount;
vkEnumerateInstanceLayerProperties(&layerCount, nullptr);
std::vector<VkLayerProperties> availableLayers(layerCount);
vkEnumerateInstanceLayerProperties(&layerCount, availableLayers.data());
return false;
}接下来,检查validationLayers中的所有图层是否存在于availableLayers列表中。你可能需要在strcmp中加入<cstring>。
for (const char* layerName : validationLayers) {
bool layerFound = false;
for (const auto& layerProperties : availableLayers) {
if (strcmp(layerName, layerProperties.layerName) == 0) {
layerFound = true;
break;
}
}
if (!layerFound) {
return false;
}
}
return true;现在我们可以在createInstance中使用这个函数。
void createInstance() {
if (enableValidationLayers && !checkValidationLayerSupport()) {
throw std::runtime_error("validation layers requested, but not available!");
}
...
}现在在调试模式下运行该程序,并确保该错误没有发生。如果发生了,那么请看一下FAQ。
最后,修改VkInstanceCreateInfo结构实例,以包括验证层名称(如果它们被启用):
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
} else {
createInfo.enabledLayerCount = 0;
}如果检查成功,那么vkCreateInstance应该不会返回VK_ERROR_LAYER_NOT_PRESENT错误,但你应该运行程序来确定。
消息回调
验证层默认会将调试信息打印到标准输出,但我们也可以通过在程序中提供一个明确的回调来自己处理这些信息。这也将允许你决定你想看到哪种信息,因为不是所有的信息都是(致命的)错误。如果你现在不想这样做,那么你可以跳到本章的最后一节。
为了在程序中设置一个回调来处理消息和相关的细节,我们必须使用VK_EXT_debug_utils扩展来设置一个带有回调的调试信使。
我们首先创建一个getRequiredExtensions函数,它将根据是否启用验证层来返回所需的扩展列表:
std::vector<const char*> getRequiredExtensions() {
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
std::vector<const char*> extensions(glfwExtensions, glfwExtensions + glfwExtensionCount);
if (enableValidationLayers) {
extensions.push_back(VK_EXT_DEBUG_UTILS_EXTENSION_NAME);
}
return extensions;
}GLFW指定的扩展总是需要的,但调试信使扩展是有条件添加的。注意,我在这里使用了VK_EXT_DEBUG_UTILS_EXTENSION_NAME宏,它等于字面字符串
VK_EXT_debug_utils。使用这个宏可以让你避免打错字。
现在我们可以在createInstance中使用这个函数。
auto extensions = getRequiredExtensions();
createInfo.enabledExtensionCount = static_cast<uint32_t>(extensions.size());
createInfo.ppEnabledExtensionNames = extensions.data();运行该程序,确保你没有收到VK_ERROR_EXTENSION_NOT_PRESENT错误。我们其实不需要检查这个扩展是否存在,因为它应该是由验证层的可用性所暗示的。
现在让我们看看调试回调函数是什么样子的。用PFN_vkDebugUtilsMessengerCallbackEXT的原型添加一个新的静态成员函数,叫做debugCallback。VKAPI_ATTR和VKAPI_CALL确保该函数具有正确的签名,以便Vulkan调用它。
static VKAPI_ATTR VkBool32 VKAPI_CALL debugCallback(
VkDebugUtilsMessageSeverityFlagBitsEXT messageSeverity,
VkDebugUtilsMessageTypeFlagsEXT messageType,
const VkDebugUtilsMessengerCallbackDataEXT* pCallbackData,
void* pUserData) {
std::cerr << "validation layer: " << pCallbackData->pMessage << std::endl;
return VK_FALSE;
}第一个参数指定消息的严重性,它是以下标志之一。
vk_debug_utils_message_severity_verbose_bit_ext: 诊断消息vk_debug_utils_message_severity_info_bit_ext: 像创建资源的信息消息vk_debug_utils_message_severity_warning_bit_ext: 关于不一定是错误的行为的消息,但很可能是您的应用程序中的一个错误。vk_debug_utils_message_severity_error_bit_ext: 关于无效行为的信息,可能导致崩溃
这个枚举的值是这样设置的,你可以使用比较操作来检查一个消息与某个严重程度相比是否相等或更坏,例如:
if (messageSeverity >= VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT) {
// Message is important enough to show
}messageType参数可以有以下值。
vk_debug_utils_message_type_general_bit_ext: 发生了一些与规范或性能无关的事件vk_debug_utils_message_type_validation_bit_ext: 发生了违反规范的事情,或表明可能有错误。vk_debug_utils_message_type_performance_bit_ext: 潜在的对Vulkan的非最佳使用
pCallbackData参数指的是一个VkDebugUtilsMessengerCallbackDataEXT结构,包含消息本身的细节,最重要的成员是。
pMessage: 调试信息是一个空尾的字符串pObjects: 与该消息相关的Vulkan对象句柄的数组objectCount: 数组中对象的数量
最后,pUserData参数包含一个在设置回调时指定的指针,允许你向它传递你自己的数据。
回调返回一个布尔值,表明触发验证层消息的Vulkan调用是否应该被终止。如果回调返回true,那么该调用将被中止,并出现VK_ERROR_VALIDATION_FAILED_EXT错误。这通常只用于测试验证层本身,所以你应该总是返回VK_FALSE。
现在剩下的就是告诉Vulkan关于回调函数的信息。也许有些令人惊讶的是,即使是Vulkan中的调试回调也是用一个需要明确创建和销毁的句柄管理的。这样的回调是调试信使的一部分,你可以有你想要的数量。在instance下为这个句柄添加一个类成员:
VkDebugUtilsMessengerEXT debugMessenger;现在添加一个函数setupDebugMessenger,从initVulkan中调用,紧接着createInstance:
void initVulkan() {
createInstance();
setupDebugMessenger();
}
void setupDebugMessenger() {
if (!enableValidationLayers) return;
}我们需要在一个结构中填写关于信使及其回调的细节:
VkDebugUtilsMessengerCreateInfoEXT createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT;
createInfo.messageSeverity = VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT;
createInfo.messageType = VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT;
createInfo.pfnUserCallback = debugCallback;
createInfo.pUserData = nullptr; // OptionalmessageSeverity字段允许你指定所有你希望你的回调被调用的严重程度类型。我在这里指定了除VK_DEBUG_UTILS_MESSAGE_SEVERITY_INFO_BIT_EXT以外的所有类型,以接收关于可能出现的问题的通知,而不包括粗略的一般调试信息。
同样,messageType字段可以让你过滤你的回调被通知的消息类型。我在这里简单地启用了所有类型。如果它们对你没有用处,你可以随时禁用一些。
最后,pfnUserCallback字段指定了回调函数的指针。你可以选择传递一个指向pUserData字段的指针,它将通过pUserData参数传递给回调函数。例如,你可以用它来传递一个指向HelloTriangleApplication类的指针。
请注意,还有很多方法可以配置验证层信息和调试回调,但对于本教程来说,这是一个很好的设置,可以开始使用。关于更多的可能性,请参见扩展规范。
这个结构应该被传递给vkCreateDebugUtilsMessengerEXT函数来创建VkDebugUtilsMessengerEXT对象。不幸的是,由于这个函数是一个扩展函数,它不会被自动加载。我们必须自己使用vkGetInstanceProcAddr来查找它的地址。我们将创建我们自己的代理函数,在后台处理这个问题。我已经把它添加到HelloTriangleApplication类定义的正上方。
VkResult CreateDebugUtilsMessengerEXT(VkInstance instance, const VkDebugUtilsMessengerCreateInfoEXT* pCreateInfo, const VkAllocationCallbacks* pAllocator, VkDebugUtilsMessengerEXT* pDebugMessenger) {
auto func = (PFN_vkCreateDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkCreateDebugUtilsMessengerEXT");
if (func != nullptr) {
return func(instance, pCreateInfo, pAllocator, pDebugMessenger);
} else {
return VK_ERROR_EXTENSION_NOT_PRESENT;
}
}vkGetInstanceProcAddr函数将返回nullptr,如果该函数不能被加载。如果它是可用的,现在我们可以调用这个函数来创建扩展对象:
if (CreateDebugUtilsMessengerEXT(instance, &createInfo, nullptr, &debugMessenger) != VK_SUCCESS) {
throw std::runtime_error("failed to set up debug messenger!");
}倒数第二个参数是可选的分配器回调,我们将其设置为 “nullptr”,除此之外的参数是相当直接的。由于调试信使是特定于我们的Vulkan实例和它的层,它需要明确地被指定为第一个参数。稍后你也会在其他子对象中看到这种模式。
VkDebugUtilsMessengerEXT对象也需要通过调用vkDestroyDebugUtilsMessengerEXT来清理。与vkCreateDebugUtilsMessengerEXT类似,该函数需要明确加载。
在CreateDebugUtilsMessengerEXT下面创建另一个代理函数。
void DestroyDebugUtilsMessengerEXT(VkInstance instance, VkDebugUtilsMessengerEXT debugMessenger, const VkAllocationCallbacks* pAllocator) {
auto func = (PFN_vkDestroyDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkDestroyDebugUtilsMessengerEXT");
if (func != nullptr) {
func(instance, debugMessenger, pAllocator);
}
}确保这个函数是一个静态的类函数或者是一个类外的函数。然后我们可以在cleanup函数中调用它。
void cleanup() {
if (enableValidationLayers) {
DestroyDebugUtilsMessengerEXT(instance, debugMessenger, nullptr);
}
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}调试实例的创建和销毁
尽管我们现在已经在程序中加入了带有验证层的调试,但我们还没有完全覆盖所有的内容。vkCreateDebugUtilsMessengerEXT调用需要一个有效的实例被创建,vkDestroyDebugUtilsMessengerEXT必须在实例被销毁前被调用。这使得我们目前无法调试vkCreateInstance和vkDestroyInstance调用中的任何问题。
然而,如果你仔细阅读扩展文档,你会发现有一种方法可以专门为这两个函数调用创建一个单独的调试工具信使。它要求你在VkInstanceCreateInfo的pNext扩展字段中简单传递一个指向VkDebugUtilsMessengerCreateInfoEXT结构的指针。首先将信使创建信息的人口提取到一个单独的函数中:
void populateDebugMessengerCreateInfo(VkDebugUtilsMessengerCreateInfoEXT& createInfo) {
createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT;
createInfo.messageSeverity = VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT;
createInfo.messageType = VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT;
createInfo.pfnUserCallback = debugCallback;
}
...
void setupDebugMessenger() {
if (!enableValidationLayers) return;
VkDebugUtilsMessengerCreateInfoEXT createInfo;
populateDebugMessengerCreateInfo(createInfo);
if (CreateDebugUtilsMessengerEXT(instance, &createInfo, nullptr, &debugMessenger) != VK_SUCCESS) {
throw std::runtime_error("failed to set up debug messenger!");
}
}现在我们可以在 “createInstance”函数中重新使用它。
void createInstance() {
...
VkInstanceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;
...
VkDebugUtilsMessengerCreateInfoEXT debugCreateInfo{};
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
populateDebugMessengerCreateInfo(debugCreateInfo);
createInfo.pNext = (VkDebugUtilsMessengerCreateInfoEXT*) &debugCreateInfo;
} else {
createInfo.enabledLayerCount = 0;
createInfo.pNext = nullptr;
}
if (vkCreateInstance(&createInfo, nullptr, &instance) != VK_SUCCESS) {
throw std::runtime_error("failed to create instance!");
}
}debugCreateInfo变量被放在if语句之外,以确保它在调用vkCreateInstance之前不会被销毁。通过这样创建一个额外的调试信使,它将在vkCreateInstance和vkDestroyInstance期间自动被使用,并在之后被清理掉。
测试
现在让我们故意犯一个错误,看看验证层的作用。暂时删除cleanup函数中对DestroyDebugUtilsMessengerEXT的调用,然后运行你的程序。一旦它退出,你应该看到类似这样的东西。
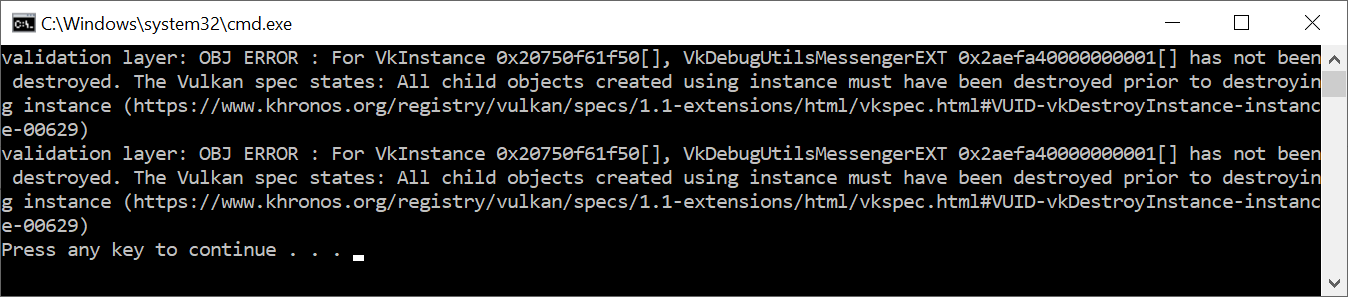
如果你没有看到任何信息,那么检查你的安装。
如果你想看哪个调用触发了一个消息,你可以在消息回调上添加一个断点,然后看一下堆栈跟踪。
配置
除了在VkDebugUtilsMessengerCreateInfoEXT结构中指定的标志,还有很多关于验证层行为的设置。浏览Vulkan
SDK并进入Config目录。在那里你会发现一个vk_layer_settings.txt文件,解释如何配置图层。
要为您自己的应用程序配置图层设置,请将该文件复制到您项目的Debug和Release目录下,并按照说明设置所需的行为。然而,在本教程的其余部分,我将假定你使用的是默认设置。
在本教程中,我将故意犯一些错误,向你展示验证层对捕捉这些错误有多大帮助,并告诉你准确了解你在Vulkan中的操作是多么重要。现在是时候看看系统中的Vulkan设备。
物理设备和队列系列
选择一个物理设备
在通过VkInstance初始化Vulkan库后,我们需要在系统中寻找并选择一个支持我们所需功能的显卡。事实上,我们可以选择任何数量的显卡并同时使用它们,但在本教程中,我们将坚持使用第一个适合我们需求的显卡。
我们将添加一个函数pickPhysicalDevice并在initVulkan函数中添加对它的调用。
void initVulkan() {
createInstance();
setupDebugMessenger();
pickPhysicalDevice();
}
void pickPhysicalDevice() {
}
我们最终选择的显卡将被存储在一个VkPhysicalDevice句柄中,它被作为一个新的类成员添加。当VkInstance被销毁时,这个对象将被隐式地销毁,所以我们不需要在清理函数中做任何新的事情。
VkPhysicalDevice physicalDevice = VK_NULL_HANDLE;
列出显卡与列出扩展名非常相似,开始时只查询数字。
uint32_t deviceCount = 0;
vkEnumeratePhysicalDevices(instance, &deviceCount, nullptr);如果有0台设备支持Vulkan,那么就没有必要再继续下去了。
if (deviceCount == 0) {
throw std::runtime_error("failed to find GPUs with Vulkan support!");
}否则我们现在可以分配一个数组来保存所有的VkPhysicalDevice句柄。
std::vector<VkPhysicalDevice> devices(deviceCount);
vkEnumeratePhysicalDevices(instance, &deviceCount, devices.data());现在,我们需要对它们中的每一个进行评估,并检查它们是否适合于我们想要执行的操作,因为不是所有的显卡都是平等的。为此,我们将引入一个新的函数。
bool isDeviceSuitable(VkPhysicalDevice device) {
return true;
}而且我们会检查是否有物理设备符合我们将添加到该功能的要求。
for (const auto& device : devices) {
if (isDeviceSuitable(device)) {
physicalDevice = device;
break;
}
}
if (physicalDevice == VK_NULL_HANDLE) {
throw std::runtime_error("failed to find a suitable GPU!");
}下一节将介绍我们将在isDeviceSuitable`函数中检查的第一批需求。随着我们在后面的章节中开始使用更多的Vulkan特性,我们也将扩展这个函数以包括更多的检查。
基础设备适用性检查
为了评估一个设备的适用性,我们可以从查询一些细节开始。基本的设备属性,如名称、类型和支持的Vulkan版本,可以使用vkGetPhysicalDeviceProperties进行查询。
VkPhysicalDeviceProperties deviceProperties;
vkGetPhysicalDeviceProperties(device, &deviceProperties);纹理压缩、64位浮点和多视口渲染(对VR有用)等可选特性的支持可以用vkGetPhysicalDeviceFeatures查询:
VkPhysicalDeviceFeatures deviceFeatures;
vkGetPhysicalDeviceFeatures(device, &deviceFeatures);还有更多的细节可以从设备中查询到,我们将在后面讨论关于设备内存和队列家族的问题(见下一节)。
举个例子,假设我们认为我们的应用程序只适用于支持几何着色器的专用图形卡。那么
isDeviceSuitable函数会是这样的:
bool isDeviceSuitable(VkPhysicalDevice device) {
VkPhysicalDeviceProperties deviceProperties;
VkPhysicalDeviceFeatures deviceFeatures;
vkGetPhysicalDeviceProperties(device, &deviceProperties);
vkGetPhysicalDeviceFeatures(device, &deviceFeatures);
return deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU &&
deviceFeatures.geometryShader;
}你可以给每个设备打分,然后选择最高的那个,而不是仅仅检查一个设备是否合适,然后选择第一个。这样,你就可以通过给专用显卡打高分而偏爱它,但如果是唯一可用的集成GPU,就可以回落到它。你可以像这样实现,如下:
#include <map>
...
void pickPhysicalDevice() {
...
// Use an ordered map to automatically sort candidates by increasing score
std::multimap<int, VkPhysicalDevice> candidates;
for (const auto& device : devices) {
int score = rateDeviceSuitability(device);
candidates.insert(std::make_pair(score, device));
}
// Check if the best candidate is suitable at all
if (candidates.rbegin()->first > 0) {
physicalDevice = candidates.rbegin()->second;
} else {
throw std::runtime_error("failed to find a suitable GPU!");
}
}
int rateDeviceSuitability(VkPhysicalDevice device) {
...
int score = 0;
// Discrete GPUs have a significant performance advantage
if (deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU) {
score += 1000;
}
// Maximum possible size of textures affects graphics quality
score += deviceProperties.limits.maxImageDimension2D;
// Application can't function without geometry shaders
if (!deviceFeatures.geometryShader) {
return 0;
}
return score;
}在本教程中,你不需要实现所有这些,但这是为了让你了解你可以如何设计你的设备选择过程。当然,你也可以只显示选择的名称,让用户进行选择。
因为我们刚刚开始,Vulkan支持是我们唯一需要的东西,因此我们将满足于任何GPU:
bool isDeviceSuitable(VkPhysicalDevice device) {
return true;
}在下一节,我们将讨论第一个真正需要检查的特征。
Queue families
之前已经简单地提到过,Vulkan中几乎所有的操作,从绘图到上传纹理,都需要将命令提交给一个队列。有不同类型的队列,它们来自不同的队列家族,每个队列家族只允许一个子集的命令。例如,可能有一个队列家族只允许处理计算命令,或者一个只允许内存传输相关的命令。
我们需要检查设备支持哪些队列家族,其中哪一个支持我们想要使用的命令。为此,我们将添加一个新的函数findQueueFamilies来寻找我们需要的所有队列家族。
现在我们只想寻找支持图形命令的队列,所以这个函数可以是这样的:
uint32_t findQueueFamilies(VkPhysicalDevice device) {
// Logic to find graphics queue family
}然而,在下一章中,我们已经要寻找另一个队列了,所以最好为此做好准备,将索引捆绑到一个结构中:
struct QueueFamilyIndices {
uint32_t graphicsFamily;
};
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
// Logic to find queue family indices to populate struct with
return indices;
}但是如果一个队列家族不可用呢?我们可以在findQueueFamilies中抛出一个异常,但是这个函数并不是决定设备适用性的正确地方。例如,我们可能喜欢有专用传输队列系列的设备,但不要求它。因此,我们需要某种方式来表明是否找到了一个特定的队列系列。
其实不可能用一个神奇的值来表示一个队列家族的不存在,因为理论上任何uint32_t的值都可以是一个有效的队列家族索引,包括0。幸运的是C++17引入了一个数据结构来区分一个值是否存在的情况:
#include <optional>
...
std::optional<uint32_t> graphicsFamily;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // false
graphicsFamily = 0;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // truestd::optional是一个包装器,在你给它赋值之前不包含任何值。在任何时候,你都可以通过调用其has_value()成员函数来查询它是否包含一个值。这意味着我们可以把逻辑改成:
#include <optional>
...
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
};
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
// Assign index to queue families that could be found
return indices;
}我们现在可以开始实际实现 findQueueFamilies:
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
...
return indices;
}检索队列家族列表的过程正是你所期望的,并使用vkGetPhysicalDeviceQueueFamilyProperties:
uint32_t queueFamilyCount = 0;
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, nullptr);
std::vector<VkQueueFamilyProperties> queueFamilies(queueFamilyCount);
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, queueFamilies.data());VkQueueFamilyProperties结构包含关于队列家族的一些细节,包括支持的操作类型和基于该家族可以创建的队列数量。我们需要找到至少一个支持VK_QUEUE_GRAPHICS_BIT的队列家族。
int i = 0;
for (const auto& queueFamily : queueFamilies) {
if (queueFamily.queueFlags & VK_QUEUE_GRAPHICS_BIT) {
indices.graphicsFamily = i;
}
i++;
}现在我们有了这个花哨的队列家族查找函数,我们可以在isDeviceSuitable函数中使用它作为检查,以确保设备可以处理我们要使用的命令:
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
return indices.graphicsFamily.has_value();
}为了使之更方便,我们还将为结构本身添加一个通用检查:
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
bool isComplete() {
return graphicsFamily.has_value();
}
};
...
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
return indices.isComplete();
}我们现在也可以用它来提前退出findQueenFamilies。
for (const auto& queueFamily : queueFamilies) {
...
if (indices.isComplete()) {
break;
}
i++;
}很好,现在我们只需要找到合适的物理设备了! 下一步是创建一个逻辑设备来与之接口。
逻辑设备和队列
介绍
在选择了一个要使用的物理设备后,我们需要设置一个逻辑设备来与之接口。逻辑设备的创建过程与实例创建过程类似,描述了我们想要使用的功能。我们还需要指定要创建哪些队列,现在我们已经查询到哪些队列系列是可用的。如果你有不同的要求,你甚至可以从同一个物理设备创建多个逻辑设备。
首先,添加一个新的类成员来存储逻辑设备句柄。
VkDevice device;接下来,添加一个createLogicalDevice函数,从initVulkan中调用。
void initVulkan() {
createInstance();
setupDebugMessenger();
pickPhysicalDevice();
createLogicalDevice();
}
void createLogicalDevice() {
}指定要创建的队列
创建一个逻辑设备需要再次在结构中指定一堆细节,其中第一个结构将是VkDeviceQueueCreateInfo。这个结构描述了我们想要的单个队列家族的队列数量。现在我们只对具有图形功能的队列感兴趣。
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
VkDeviceQueueCreateInfo queueCreateInfo{};
queueCreateInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueCreateInfo.queueFamilyIndex = indices.graphicsFamily.value();
queueCreateInfo.queueCount = 1;目前可用的驱动程序只允许你为每个队列家族创建少量的队列,你其实不需要超过一个。这是因为你可以在多个线程上创建所有的命令缓冲区,然后用一个低开销的调用在主线程上一次性提交它们。
Vulkan让你为队列分配优先级,以影响命令缓冲区执行的调度,使用0.0和1.0之间的浮点数字。即使只有一个队列,也需要这样做:
float queuePriority = 1.0f;
queueCreateInfo.pQueuePriorities = &queuePriority;指定使用的设备特性
下一个要指定的信息是我们要使用的设备特性集。这些是我们在前一章用vkGetPhysicalDeviceFeatures查询支持的特性,如几何着色器。现在我们不需要什么特别的东西,所以我们可以简单地定义它,并把所有东西都留到VK_FALSE。一旦我们要开始用Vulkan做更多有趣的事情,我们就会回到这个结构。
VkPhysicalDeviceFeatures deviceFeatures{};创建逻辑设备
有了前面两个结构,我们可以开始填写主VkDeviceCreateInfo结构。
VkDeviceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;首先添加指向队列创建信息和设备特征结构的指针。
createInfo.pQueueCreateInfos = &queueCreateInfo;
createInfo.queueCreateInfoCount = 1;
createInfo.pEnabledFeatures = &deviceFeatures;其余的信息与VkInstanceCreateInfo结构相似,要求你指定扩展和验证层。不同的是,这一次这些是设备特定的。
设备特定扩展的一个例子是VK_KHR_swapchain,它允许你将该设备的渲染图像呈现给窗口。系统中可能有一些Vulkan设备缺乏这种能力,比如说因为它们只支持计算操作。我们将在交换链章节中再来讨论这个扩展。
以前的Vulkan实现对实例和设备特定的验证层进行了区分,但现在不再是这样了。这意味着VkDeviceCreateInfo的enabledLayerCount和ppEnabledLayerNames字段会被最新的实现所忽略。然而,为了与旧的实现兼容,设置它们仍然是一个好主意:
createInfo.enabledExtensionCount = 0;
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
} else {
createInfo.enabledLayerCount = 0;
}我们现在不需要任何特定的设备扩展。
就这样,我们现在准备调用适当命名的vkCreateDevice函数来实例化这个逻辑设备。
if (vkCreateDevice(physicalDevice, &createInfo, nullptr, &device) != VK_SUCCESS) {
throw std::runtime_error("failed to create logical device!");
}参数是要连接的物理设备、我们刚刚指定的队列和使用信息、可选的分配回调指针和一个变量的指针,用于存储逻辑设备句柄。与实例创建函数类似,这个调用可以基于启用不存在的扩展或指定不支持的功能的期望用法而返回错误。
该设备应在cleanup中用vkDestroyDevice函数销毁:
void cleanup() {
vkDestroyDevice(device, nullptr);
...
}逻辑设备不与实例直接交互,这就是为什么它不作为一个参数包括在内。
检索队列句柄
这些队列是和逻辑设备一起自动创建的,但我们还没有一个句柄来连接它们。首先添加一个类成员来存储图形队列的句柄。
VkQueue graphicsQueue;设备队列在设备被销毁时被隐式清理,所以我们不需要在cleanup中做任何事情。
我们可以使用vkGetDeviceQueue函数来检索每个队列家族的队列柄。参数是逻辑设备、队列家族、队列索引和一个指向变量的指针,用于存储队列手柄。因为我们只在这个系列中创建一个队列,所以我们将简单地使用索引0。
vkGetDeviceQueue(device, indices.graphicsFamily.value(), 0, &graphicsQueue)。有了逻辑设备和队列句柄,我们现在可以真正开始使用显卡做事情了! 在接下来的几章中,我们将设置资源来向窗口系统展示结果。
展示
窗口表面
由于Vulkan是一个与平台无关的API,它自己不能直接与窗口系统对接。为了在Vulkan和窗口系统之间建立连接,将结果呈现在屏幕上,我们需要使用WSI(窗口系统集成)扩展。在本章中,我们将讨论第一个,即VK_KHR_surface。它暴露了一个
VkSurfaceKHR对象,它代表了一种抽象的表面类型,用于呈现渲染的图像。我们程序中的表面将由我们已经用GLFW打开的窗口来支持。
VK_KHR_surface扩展是一个实例级的扩展,实际上我们已经启用了它,因为它被包含在glfwGetRequiredInstanceExtensions返回的列表中。列表中还包括一些其他的WSI扩展,我们将在接下来的几章中使用。
窗口表面需要在实例创建后立即创建,因为它实际上可以影响物理设备的选择。我们之所以推迟这一步骤,是因为窗口表面是渲染目标和展示这一更大主题的一部分,对它的解释会使基本设置变得混乱。还应该注意的是,如果你只是需要离屏渲染,那么窗口表面在Vulkan中是一个完全可有可无的组件。Vulkan允许你这样做,而不需要像创建一个不可见的窗口(OpenGL所必需的)那样的黑客。
窗口表面的创建
首先,在调试回调的下面添加一个surface类成员。
VkSurfaceKHR surface;尽管VkSurfaceKHR对象和它的使用是与平台无关的,但它的创建却不是,因为它依赖于窗口系统细节。例如,在Windows下它需要HWND和HMODULE句柄。因此,有一个平台特定的扩展,在Windows上被称为VK_KHR_win32_surface,也被自动包含在glfwGetRequiredInstanceExtensions的列表中。
我将演示如何在Windows上使用这个平台特定的扩展来创建一个表面,但在本教程中我们不会实际使用它。使用像GLFW这样的库,然后继续使用特定平台的代码,反正没有任何意义。GLFW实际上有glfwCreateWindowSurface,为我们处理平台差异。不过,在我们开始依赖它之前,看看它在幕后做了些什么还是不错的。
要访问本地平台的功能,你需要更新顶部的includes。
#define VK_USE_PLATFORM_WIN32_KHR
#define GLFW_INCLUDE_VULKAN
#include <GLFW/glfw3.h>
#define GLFW_EXPOSE_NATIVE_WIN32
#include <GLFW/glfw3native.h>因为窗口表面是一个Vulkan对象,它自带的VkWin32SurfaceCreateInfoKHR结构需要被填入。它有两个重要的参数。hwnd和hinstance。这些是窗口和进程的句柄。
VkWin32SurfaceCreateInfoKHR createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR;
createInfo.hwnd = glfwGetWin32Window(window);
createInfo.hinstance = GetModuleHandle(nullptr);glfwGetWin32Window函数用于从GLFW窗口对象获得原始HWND。GetModuleHandle调用返回当前进程的HINSTANCE手柄。
之后可以用vkCreateWin32SurfaceKHR来创建表面,其中包括实例参数、表面创建细节、自定义分配器和表面句柄要存储的变量。从技术上讲,这是一个WSI扩展函数,但是它非常常用,以至于标准的Vulkan加载器包含了它,所以与其他扩展不同,你不需要明确加载它。
if (vkCreateWin32SurfaceKHR(instance, &createInfo, nullptr, &surface) != VK_SUCCESS) {
throw std::runtime_error("failed to create window surface!");
}这个过程对于其他平台如Linux也是类似的,vkCreateXcbSurfaceKHR将一个XCB连接和窗口作为X11的创建细节。
glfwCreateWindowSurface函数正是执行这个操作,每个平台有不同的实现。我们现在将它整合到我们的程序中。添加一个函数createSurface,在实例创建和setupDebugMessenger之后立即从initVulkan调用。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
}
void createSurface() {
}GLFW调用需要简单的参数,而不是结构,这使得函数的实现非常简单明了:
void createSurface() {
if (glfwCreateWindowSurface(instance, window, nullptr, &surface) != VK_SUCCESS) {
throw std::runtime_error("failed to create window surface!");
}
}参数是VkInstance、GLFW窗口指针、自定义分配器和指向VkSurfaceKHR变量的指针。它只是通过相关平台调用的VkResult。GLFW没有提供销毁surface的特殊函数,但这可以很容易地通过原始API完成:
void cleanup() {
...
vkDestroySurfaceKHR(instance, surface, nullptr);
vkDestroyInstance(instance, nullptr);
...
}确保在实例之前,surface被销毁了。
查询展示支持
尽管Vulkan的实现可能支持窗口系统集成,但这并不意味着系统中的每个设备都支持它。因此我们需要扩展isDeviceSuitable以确保设备可以向我们创建的表面呈现图像。由于呈现是一个队列特定的功能,问题实际上是要找到一个支持向我们创建的表面呈现的队列家族。
实际上,支持绘图命令的队列族和支持展示的队列族有可能不重叠。因此我们必须考虑到,通过修改QueueFamilyIndices结构,可能会有一个独特的展示队列:
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
std::optional<uint32_t> presentFamily;
bool isComplete() {
return graphicsFamily.has_value() && presentFamily.has_value();
}
};接下来,我们将修改findQueueFamilies函数,以寻找一个有能力呈现给我们窗口表面的队列家族。检查的函数是vkGetPhysicalDeviceSurfaceSupportKHR,它接收物理设备、队列家族索引和表面作为参数。在VK_QUEUE_GRAPHICS_BIT的同一循环中加入对它的调用:
VkBool32 presentSupport = false;
vkGetPhysicalDeviceSurfaceSupportKHR(device, i, surface, &presentSupport);然后简单地检查布尔值,并存储展示家庭队列索引:
if (presentSupport) {
indices.presentFamily = i;
}请注意,这些最终很可能是同一个队列系列,但在整个程序中,为了统一方法,我们将把它们当作独立的队列。尽管如此,你可以添加逻辑,明确地倾向于在同一个队列中支持绘图和展示的物理设备,以提高性能。
创建展示队列
剩下的就是修改逻辑设备创建程序,以创建展示队列并检索VkQueue句柄。为句柄添加一个成员变量:
VkQueue presentQueue;接下来,我们需要有多个VkDeviceQueueCreateInfo结构来创建两个家族的队列。一个优雅的方法是创建一个所有独特的队列家族的集合,这对所需的队列来说是必要的:
#include <set>
...
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
std::vector<VkDeviceQueueCreateInfo> queueCreateInfos;
std::set<uint32_t> uniqueQueueFamilies = {indices.graphicsFamily.value(), indices.presentFamily.value()};
float queuePriority = 1.0f;
for (uint32_t queueFamily : uniqueQueueFamilies) {
VkDeviceQueueCreateInfo queueCreateInfo{};
queueCreateInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueCreateInfo.queueFamilyIndex = queueFamily;
queueCreateInfo.queueCount = 1;
queueCreateInfo.pQueuePriorities = &queuePriority;
queueCreateInfos.push_back(queueCreateInfo);
}并修改VkDeviceCreateInfo以指向矢量:
createInfo.queueCreateInfoCount = static_cast<uint32_t>(queueCreateInfos.size());
createInfo.pQueueCreateInfos = queueCreateInfos.data();如果队列家族是相同的,那么我们只需要传递一次它的索引。最后,添加一个调用来检索队列句柄:
vkGetDeviceQueue(device, indices.presentFamily.value(), 0, &presentQueue);在队列族相同的情况下,这两个 手柄现在很可能有相同的值。在下一章中,我们要看一下交换链,以及它们如何给我们提供向表面呈现图像的能力。
交换链
Vulkan没有 “默认帧缓冲区”的概念,因此它需要一个基础设施,在我们将缓冲区在屏幕上可视化之前,它将拥有我们要渲染的缓冲区。这个基础设施被称为交换链,必须在Vulkan中明确创建。交换链本质上是一个等待被呈现到屏幕上的图像队列。我们的应用程序将获取这样的图像来绘制它,然后将其返回到队列中。队列究竟如何工作以及从队列中呈现图像的条件取决于交换链是如何设置的,但是交换链的一般目的是使图像的呈现与屏幕的刷新率同步。
检查交换链的支持情况
由于各种原因,并不是所有的显卡都能够直接将图像呈现在屏幕上,例如因为它们是为服务器设计的,没有任何显示输出。其次,由于图像呈现与窗口系统和与窗口相关的表面有很大的关系,所以它实际上不是Vulkan核心的一部分。你必须在查询到VK_KHR_swapchain设备扩展的支持后启用它。
为此,我们将首先扩展isDeviceSuitable函数来检查这个扩展是否被支持。我们之前已经看到如何列出VkPhysicalDevice所支持的扩展,所以这样做应该是相当简单的。注意Vulkan头文件提供了一个很好的宏VK_KHR_SWAPCHAIN_EXTENSION_NAME,它被定义为VK_KHR_swapchain。使用这个宏的好处是,编译器会捕捉到错误的拼写。
首先声明一个所需设备扩展的列表,类似于要启用的验证层列表:
const std::vector<const char*> deviceExtensions = {
VK_KHR_SWAPCHAIN_EXTENSION_NAME
};接下来,创建一个新的函数checkDeviceExtensionSupport,从isDeviceSuitable调用,作为额外的检查。
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
bool extensionsSupported = checkDeviceExtensionSupport(device);
return indices.isComplete() && extensionsSupported;
}
bool checkDeviceExtensionSupport(VkPhysicalDevice device) {
return true;
}修改函数的主体以列举扩展名,并检查所有需要的扩展名是否在其中。
bool checkDeviceExtensionSupport(VkPhysicalDevice device) {
uint32_t extensionCount;
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, nullptr);
std::vector<VkExtensionProperties> availableExtensions(extensionCount);
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, availableExtensions.data());
std::set<std::string> requiredExtensions(deviceExtensions.begin(), deviceExtensions.end());
for (const auto& extension : availableExtensions) {
requiredExtensions.erase(extension.extensionName);
}
return requiredExtensions.empty();
}我在这里选择使用一组字符串来表示未确认的所需扩展。这样我们就可以在列举可用扩展序列的时候轻松地勾选它们。当然,你也可以像checkValidationLayerSupport那样使用嵌套循环。性能差异是不重要的。现在运行代码并验证你的显卡确实能够创建一个交换链。应该注意的是,正如我们在前一章中检查的那样,演示队列的可用性意味着必须支持交换链的扩展。然而,对事情的明确性还是很好的,扩展必须被明确地启用。
启用设备扩展
使用交换链需要首先启用VK_KHR_swapchain扩展。启用该扩展只需要对逻辑设备的创建结构做一个小小的改变:
createInfo.enabledExtensionCount = static_cast<uint32_t>(deviceExtensions.size());
createInfo.ppEnabledExtensionNames = deviceExtensions.data();当你这样做时,请确保替换现有的行createInfo.enabledExtensionCount = 0;。
查询互换链支持的细节
仅仅检查一个交换链是否可用是不够的,因为它可能实际上与我们的窗口表面不兼容。创建交换链还涉及到比创建实例和设备更多的设置,所以在我们能够继续之前,我们需要查询一些更多的细节。
基本上有三种属性是我们需要检查的。
- 基本表面能力(交换链中图像的最小/最大数量,图像的最小/最大宽度和高度)
- 表面格式(像素格式、色彩空间)
- 可用的表现模式
与findQueueFamilies类似,我们将使用一个结构来传递这些细节,一旦它们被查询到。上述三种类型的属性是以下列结构和结构列表的形式出现的:
struct SwapChainSupportDetails {
VkSurfaceCapabilitiesKHR capabilities;
std::vector<VkSurfaceFormatKHR> formats;
std::vector<VkPresentModeKHR> presentModes;
};现在我们将创建一个新的函数querySwapChainSupport,它将填充这个结构。
SwapChainSupportDetails querySwapChainSupport(VkPhysicalDevice device) {
SwapChainSupportDetails details;
return details;
}本节介绍了如何查询包含这些信息的结构。下一节将讨论这些结构的含义以及它们到底包含哪些数据。
让我们从基本的表面能力开始。这些属性的查询很简单,并被返回到一个VkSurfaceCapabilitiesKHR结构中。
vkGetPhysicalDeviceSurfaceCapabilitiesKHR(device, surface, &details.capabilities);这个函数在确定支持的能力时考虑到指定的VkPhysicalDevice和VkSurfaceKHR窗口表面。所有的支持查询函数都将这两个作为第一参数,因为它们是交换链的核心部件。
下一步是关于查询支持的表面格式。因为这是一个结构列表,它遵循熟悉的2个函数调用的仪式:
uint32_t formatCount;
vkGetPhysicalDeviceSurfaceFormatsKHR(device, surface, &formatCount, nullptr);
if (formatCount != 0) {
details.formats.resize(formatCount);
vkGetPhysicalDeviceSurfaceFormatsKHR(device, surface, &formatCount, details.formats.data());
}确保矢量的大小被调整到可以容纳所有可用的格式。最后,查询支持的演示模式与vkGetPhysicalDeviceSurfacePresentModesKHR的工作方式完全相同。
uint32_t presentModeCount;
vkGetPhysicalDeviceSurfacePresentModesKHR(device, surface, &presentModeCount, nullptr);
if (presentModeCount != 0) {
details.presentModes.resize(presentModeCount);
vkGetPhysicalDeviceSurfacePresentModesKHR(device, surface, &presentModeCount, details.presentModes.data());
}现在所有的细节都在结构中,所以让我们再一次扩展isDeviceSuitable,利用这个函数来验证交换链支持是否足够。在本教程中,如果至少有一种支持的图像格式和一种支持的演示模式,那么交换链支持就足够了,因为我们的窗口表面。
bool swapChainAdequate = false;
if (extensionsSupported) {
SwapChainSupportDetails swapChainSupport = querySwapChainSupport(device);
swapChainAdequate = !swapChainSupport.formats.empty() && !swapChainSupport.presentModes.empty();
}重要的是,我们只有在验证了扩展是可用的之后,才尝试查询交换链的支持。该函数的最后一行改为。
return indices.isComplete() && extensionsSupported && swapChainAdequate;为交换链选择正确的设置
如果满足了swapChainAdequate的条件,那么支持肯定是足够的,但是仍然可能有许多不同的模式,有不同的优化。我们现在要写几个函数来找到最佳交换链的正确设置。有三种类型的设置需要确定。
- 表面格式(颜色深度)
- 演示模式(将图像 “交换”到屏幕上的条件)
- 交换范围(交换链中图像的分辨率)
对于这些设置中的每一个,我们都会有一个理想的值,如果有的话,我们就会采用这个值,否则,我们就会建立一些逻辑来寻找下一个最佳值。
表面格式
这个设置的函数是这样开始的。我们稍后会将SwapChainSupportDetails结构中的formats成员作为参数传给他。
VkSurfaceFormatKHR chooseSwapSurfaceFormat(const std::vector<VkSurfaceFormatKHR>& availableFormats) {
}每个VkSurfaceFormatKHR'条目包含一个format’和一个colorSpace'成员。format成员指定了颜色通道和类型。例如,VK_FORMAT_B8G8R8A8_SRGB意味着我们以8位无符号整数的顺序来存储B、G、R和alpha通道,每个像素共有32位。colorSpace成员使用VK_COLOR_SPACE_SRGB_NONLINEAR_KHR标志指示是否支持SRGB颜色空间。注意,这个标志在旧版本的规范中曾被称为VK_COLORSPACE_SRGB_NONLINEAR_KHR`。
对于颜色空间,如果有的话,我们会使用SRGB,因为它会产生更准确的感知颜色。它也几乎是图像的标准颜色空间,比如我们以后要使用的纹理。正因为如此,我们也应该使用SRGB颜色格式,其中最常见的一种是VK_FORMAT_B8G8R8A8_SRGB。
让我们浏览一下列表,看看是否有首选的组合:
for (const auto& availableFormat : availableFormats) {
if (availableFormat.format == VK_FORMAT_B8G8R8A8_SRGB && availableFormat.colorSpace == VK_COLOR_SPACE_SRGB_NONLINEAR_KHR) {
return availableFormat;
}
}如果这也失败了,那么我们可以开始根据现有格式的 “好”坏进行排名,但在大多数情况下,只要满足于第一个指定的格式就可以了。
VkSurfaceFormatKHR chooseSwapSurfaceFormat(const std::vector<VkSurfaceFormatKHR>& availableFormats) {
for (const auto& availableFormat : availableFormats) {
if (availableFormat.format == VK_FORMAT_B8G8R8A8_SRGB && availableFormat.colorSpace == VK_COLOR_SPACE_SRGB_NONLINEAR_KHR) {
return availableFormat;
}
}
return availableFormats[0];
}演示模式
演示模式可以说是交换链最重要的设置,因为它代表了向屏幕显示图像的实际条件。在Vulkan中,有四种可能的模式可用。
vk_present_mode_immediate_khr。你的应用程序提交的图像会立即传输到屏幕上,这可能会导致撕裂。vk_present_mode_fifo_khr。交换链是一个队列,当显示器刷新时,显示器从队列的前面取走一个图像,程序在队列的后面插入渲染好的图像。如果队列已经满了,那么程序就必须等待。这与现代游戏中的垂直同步最为相似。显示屏被刷新的时刻被称为 “垂直空白”。vk_present_mode_fifo_relaxed_khr: 这种模式只有在应用较晚并且在最后一次垂直空白时队列是空的情况下才与前一种模式不同。当图像最终到达时,不是等待下一个垂直空白,而是立即传输。这可能会导致可见的撕裂现象。vk_present_mode_mailbox_khr。这是第二种模式的另一种变化。当队列满了的时候,不是阻塞应用程序,而是简单地用较新的图像替换已经在队列中的图像。这种模式可以用来尽可能快地渲染帧,同时还能避免撕裂,导致比标准垂直同步更少的延迟问题。这通常被称为 “三重缓冲”,尽管仅有三个缓冲的存在并不一定意味着帧率的解锁。
只有VK_PRESENT_MODE_FIFO_KHR模式是可以保证的,所以我们又要写一个函数来寻找可用的最佳模式:
VkPresentModeKHR chooseSwapPresentMode(const std::vector<VkPresentModeKHR>& availablePresentModes) {
return VK_PRESENT_MODE_FIFO_KHR;
}我个人认为,如果不考虑能耗,VK_PRESENT_MODE_MAILBOX_KHR是一个非常好的权衡。它允许我们在避免撕裂的同时,通过渲染尽可能最新的图像,保持相当低的延迟,直到垂直空白。在移动设备上,能源使用更重要,你可能想使用VK_PRESENT_MODE_FIFO_KHR来代替。现在,让我们看一下列表,看看VK_PRESENT_MODE_MAILBOX_KHR是否可用。
VkPresentModeKHR chooseSwapPresentMode(const std::vector<VkPresentModeKHR>& availablePresentModes) {
for (const auto& availablePresentMode : availablePresentModes) {
if (availablePresentMode == VK_PRESENT_MODE_MAILBOX_KHR) {
return availablePresentMode;
}
}
return VK_PRESENT_MODE_FIFO_KHR;
}互换范围
这就只剩下一个主要属性,为此我们将添加最后一个函数。
VkExtent2D chooseSwapExtent(const VkSurfaceCapabilitiesKHR& capabilities) {
}交换范围是交换链图像的分辨率,它几乎总是完全等于我们要绘制的窗口的分辨率*,以像素为单位(稍后再详细说明)。可能的分辨率范围在
“VkSurfaceCapabilitiesKHR”结构中定义。Vulkan告诉我们要通过设置currentExtent成员的宽度和高度来匹配窗口的分辨率。然而,一些窗口管理器确实允许我们在这里有所区别,这可以通过将currentExtent中的宽度和高度设置为一个特殊的值来表示:uint32_t的最大值。在这种情况下,我们将在minImageExtent'和maxImageExtent’的范围内挑选与窗口最匹配的分辨率。但是我们必须以正确的单位来指定分辨率。
GLFW在测量尺寸时使用两个单位:像素和屏幕坐标。例如,我们之前在创建窗口时指定的分辨率{WIDTH, HEIGHT}是以屏幕坐标测量的。但是Vulkan是用像素工作的,所以交换链的范围也必须用像素指定。不幸的是,如果你使用的是高DPI显示器(比如苹果的Retina显示器),屏幕坐标并不对应于像素。相反,由于像素密度较高,窗口的像素分辨率会比屏幕坐标的分辨率大。因此,如果Vulkan不为我们固定交换范围,我们就不能只使用原来的{WIDTH, HEIGHT}。相反,我们必须使用glfwGetFramebufferSize来查询窗口的像素分辨率,然后再与最小和最大图像范围相匹配。
#include <cstdint> // Necessary for uint32_t
#include <limits> // Necessary for std::numeric_limits
#include <algorithm> // Necessary for std::clamp
...
VkExtent2D chooseSwapExtent(const VkSurfaceCapabilitiesKHR& capabilities) {
if (capabilities.currentExtent.width != std::numeric_limits<uint32_t>::max()) {
return capabilities.currentExtent;
} else {
int width, height;
glfwGetFramebufferSize(window, &width, &height);
VkExtent2D actualExtent = {
static_cast<uint32_t>(width),
static_cast<uint32_t>(height)
};
actualExtent.width = std::clamp(actualExtent.width, capabilities.minImageExtent.width, capabilities.maxImageExtent.width);
actualExtent.height = std::clamp(actualExtent.height, capabilities.minImageExtent.height, capabilities.maxImageExtent.height);
return actualExtent;
}
}这里使用 “clamp”函数将 “width”和 “height”的值限定在实现所支持的最小和最大范围内。
创建互换链
现在我们有了所有这些辅助函数,协助我们在运行时做出选择,我们终于有了创建一个工作交换链所需的所有信息。
创建一个 “createSwapChain”函数,从这些调用的结果开始,并确保在逻辑设备创建后从 “initVulkan”调用它。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
}
void createSwapChain() {
SwapChainSupportDetails swapChainSupport = querySwapChainSupport(physicalDevice);
VkSurfaceFormatKHR surfaceFormat = chooseSwapSurfaceFormat(swapChainSupport.formats);
VkPresentModeKHR presentMode = chooseSwapPresentMode(swapChainSupport.presentModes);
VkExtent2D extent = chooseSwapExtent(swapChainSupport.capabilities);
}除了这些属性之外,我们还必须决定我们希望在交换链中拥有多少图像。该实现指定了它所需要的最低数量,以便发挥作用。
uint32_t imageCount = swapChainSupport.capabilities.minImageCount;然而,简单地坚持这个最小值意味着我们有时可能不得不等待驱动程序完成内部操作,然后才能获取另一个图像进行渲染。因此,我们建议至少要比最小值多请求一个图像。
uint32_t imageCount = swapChainSupport.capabilities.minImageCount + 1;我们还应该确保在做这件事的时候不要超过最大的图片数量,其中0是一个特殊的值,意味着没有最大的数量。
if (swapChainSupport.capabilities.maxImageCount > 0 && imageCount > swapChainSupport.capabilities.maxImageCount) {
imageCount = swapChainSupport.capabilities.maxImageCount;
}正如Vulkan对象的传统,创建交换链对象需要填写一个大的结构。它的开始是非常熟悉的。
VkSwapchainCreateInfoKHR createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SWAPCHAIN_CREATE_INFO_KHR;
createInfo.surface = surface;在指定互换链应该与哪个表面绑定后,指定互换链图像的细节。
createInfo.minImageCount = imageCount;
createInfo.imageFormat = surfaceFormat.format;
createInfo.imageColorSpace = surfaceFormat.colorSpace;
createInfo.imageExtent = extent;
createInfo.imageArrayLayers = 1;
createInfo.imageUsage = VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT;imageArrayLayers指定了每个图像所包含的层数。除非你正在开发一个立体的3D应用程序,否则这总是1。imageUsage位字段指定了我们将在交换链中使用图像的哪种操作。在本教程中,我们将直接对它们进行渲染,这意味着它们被用作颜色附件。也有可能你会先将图像渲染到一个单独的图像上,以执行后期处理等操作。在这种情况下,你可以使用VK_IMAGE_USAGE_TRANSFER_DST_BIT这样的值来代替,并使用内存操作将渲染的图像转移到交换链图像上。
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
uint32_t queueFamilyIndices[] = {indices.graphicsFamily.value(), indices.presentFamily.value()};
if (indices.graphicsFamily != indices.presentFamily) {
createInfo.imageSharingMode = VK_SHARING_MODE_CONCURRENT;
createInfo.queueFamilyIndexCount = 2;
createInfo.pQueueFamilyIndices = queueFamilyIndices;
} else {
createInfo.imageSharingMode = VK_SHARING_MODE_EXCLUSIVE;
createInfo.queueFamilyIndexCount = 0; // Optional
createInfo.pQueueFamilyIndices = nullptr; // Optional
}接下来,我们需要指定如何处理将在多个队列家族中使用的交换链图像。在我们的应用程序中,如果图形队列系列与演示队列不同,就会出现这种情况。我们将从图形队列中绘制交换链中的图像,然后在演示队列中提交它们。有两种方法来处理从多个队列访问的图像。
vk_sharing_mode_exclusive。一个图像一次由一个队列家族拥有,在另一个队列家族中使用它之前,必须明确转移所有权。这个选项提供了最好的性能。vk_sharing_mode_concurrent。图像可以在多个队列家族中使用,无需明确的所有权转移。
如果队列家族不同,那么我们将在本教程中使用并发模式,以避免做所有权的章节,因为这些涉及到一些概念,最好在以后的时间解释。并发模式要求你使用queueFamilyIndexCount'和pQueFamilyIndices’参数事先指定哪些队列家族将共享所有权。如果图形队列家族和演示队列家族是相同的,在大多数硬件上都是如此,那么我们应该坚持使用独占模式,因为并发模式要求你至少指定两个不同的队列家族。
createInfo.preTransform = swapChainSupport.capabilities.currentTransform;我们可以指定在交换链中,如果支持某种变换(capabilities中的supportedTransforms`),就应该将其应用到图像上,比如顺时针旋转90度或水平翻转。要指定你不想要任何变换,只需指定当前的变换。
createInfo.compositeAlpha = VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR;compositeAlpha字段指定了是否应该使用alpha通道与窗口系统中的其他窗口进行混合。你几乎总是想简单地忽略alpha通道,因此VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR。
createInfo.presentMode = presentMode;
createInfo.clipped = VK_TRUE;presentMode成员不言自明。如果clipped成员被设置为VK_TRUE,那么这意味着我们不关心那些被遮挡的像素的颜色,例如因为另一个窗口在它们前面。除非你真的需要能够读回这些像素并得到可预测的结果,否则你将通过启用剪切得到最佳性能。
createInfo.oldSwapchain = VK_NULL_HANDLE;这就留下了最后一个字段,`oldSwapChain’。在Vulkan中,你的交换链有可能在你的应用程序运行时变得无效或未被优化,例如因为窗口被调整了大小。在这种情况下,交换链实际上需要从头开始创建,必须在这个字段中指定对旧交换链的引用。这是一个复杂的话题,我们将在未来的章节中进一步了解。现在我们假设我们只创建一个交换链。
现在添加一个类成员来存储VkSwapchainKHR对象:
VkSwapchainKHR swapChain;现在创建交换链就像调用vkCreateSwapchainKHR一样简单。
if (vkCreateSwapchainKHR(device, &createInfo, nullptr, &swapChain) != VK_SUCCESS) {
throw std::runtime_error("failed to create swap chain!");
}参数是逻辑设备、交换链创建信息、可选的自定义分配器和一个指向变量的指针,用于存储手柄。这里没有什么惊喜。它应该在设备前用vkDestroySwapchainKHR来清理。
void cleanup() {
vkDestroySwapchainKHR(device, swapChain, nullptr);
...
}现在运行应用程序以确保交换链被成功创建!
如果此时你在vkCreateSwapchainKHR中得到一个访问违反的错误,或者看到类似在层SteamOverlayVulkanLayer.dll中找不到’vkGetInstanceProcAddress’的消息,那么请看关于Steam覆盖层的FAQ条目 。
试着在启用验证层的情况下删除createInfo.imageExtent = extent;一行。你会发现其中一个验证层会立即抓住这个错误,并打印出一条有用的信息:

检索互换链图像
现在已经创建了交换链,所以剩下的就是检索其中的VkImage的手柄了。在后面的章节中,我们将在渲染操作中引用这些手柄。添加一个类成员来存储句柄。
std::vector<VkImage> swapChainImages;这些图像是由交换链的实现创建的,一旦交换链被销毁,它们将被自动清理,因此我们不需要添加任何清理代码。
我在createSwapChain'函数的末尾添加了检索句柄的代码,就在vkCreateSwapchainKHR’调用之后。检索它们与我们从Vulkan中检索对象数组的其他时候非常相似。请记住,我们只指定了交换链中图像的最低数量,所以实现允许创建一个有更多图像的交换链。这就是为什么我们要先用vkGetSwapchainImagesKHR查询最终的图像数量,然后调整容器的大小,最后再调用它来检索手柄。
vkGetSwapchainImagesKHR(device, swapChain, &imageCount, nullptr);
swapChainImages.resize(imageCount);
vkGetSwapchainImagesKHR(device, swapChain, &imageCount, swapChainImages.data());最后一件事,将我们为交换链图像选择的格式和范围存储在成员变量中。我们在未来的章节中会用到它们。
VkSwapchainKHR swapChain;
std::vector<VkImage> swapChainImages;
VkFormat swapChainImageFormat;
VkExtent2D swapChainExtent;
...
swapChainImageFormat = surfaceFormat.format;
swapChainExtent = extent;我们现在有了一组可以被绘制的图像,并且可以呈现在窗口上。下一章将开始介绍我们如何将图像设置为渲染目标,然后我们将开始研究实际的图形管道和绘图命令。
图像视图
为了在渲染管道中使用任何VkImage,包括交换链中的对象,我们必须创建一个VkImageView对象。图像视图实际上是对图像的一种观察。它描述了如何访问图像以及访问图像的哪一部分,例如,如果它应该被当作一个没有任何mipmapping层的2D纹理深度纹理。
在这一章中,我们将编写一个createImageViews函数,为交换链中的每个图像创建一个基本的图像视图,这样我们就可以在以后将它们作为颜色目标。
首先添加一个类成员来存储图像视图。
std::vector<VkImageView> swapChainImageViews;创建createImageViews函数,并在交换链创建后立即调用它。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
}
void createImageViews() {
}我们需要做的第一件事是调整列表的大小,以适应我们将要创建的所有图像视图。
void createImageViews() {
swapChainImageViews.resize(swapChainImages.size());
}接下来,设置循环,在所有交换链图像上进行迭代。
for (size_t i = 0; i < swapChainImages.size(); i++) {
}创建图像视图的参数在VkImageViewCreateInfo结构中指定。前面的几个参数是直接的。
VkImageViewCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO;
createInfo.image = swapChainImages[i];viewType 和
format字段指定了图像数据的解释方式。viewType参数允许你将图像视为一维纹理、二维纹理、三维纹理和立方体地图。
createInfo.viewType = VK_IMAGE_VIEW_TYPE_2D;
createInfo.format = swapChainImageFormat;components字段允许你对颜色通道进行旋转。例如,你可以把所有的通道都映射到红色通道上,形成一个单色纹理。你也可以将0和1的常量值映射到一个通道。在我们的例子中,我们将坚持使用默认的映射。
createInfo.components.r = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.g = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.b = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.a = VK_COMPONENT_SWIZZLE_IDENTITY;subresourceRange字段描述了图像的目的是什么,应该访问图像的哪一部分。我们的图像将被用作颜色目标,没有任何mipmapping级别或多个层次。
createInfo.subresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
createInfo.subresourceRange.baseMipLevel = 0;
createInfo.subresourceRange.levelCount = 1;
createInfo.subresourceRange.baseArrayLayer = 0;
createInfo.subresourceRange.layerCount = 1;如果你在做一个立体的3D应用程序,那么你将创建一个具有多个层的交换链。然后你可以通过访问不同的图层为每个图像创建多个图像视图,代表左眼和右眼的视图。
现在创建图像视图是调用vkCreateImageView的问题:
if (vkCreateImageView(device, &createInfo, nullptr, &swapChainImageViews[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create image views!");
}与图像不同,图像视图是由我们明确创建的,所以我们需要添加一个类似的循环,在程序结束时再次销毁它们:
void cleanup() {
for (auto imageView : swapChainImageViews) {
vkDestroyImageView(device, imageView, nullptr);
}
...
}一个图像视图足以开始使用图像作为纹理,但它还没有准备好作为一个渲染目标。这需要多一步的转换,即所谓的帧缓冲区。但首先我们必须建立图形管道。
图形管线基础
介绍
在接下来的几章中,我们将设置一个图形管道,并将其配置为绘制我们的第一个三角形。图形管道是将网格的顶点和纹理一直带到渲染目标中的像素的操作序列。下面是一个简图:

输入装配从你指定的缓冲区收集原始顶点数据,也可以使用索引缓冲区来重复某些元素,而不必重复顶点数据本身。
顶点着色器为每个顶点运行,并通常应用变换来将顶点位置从模型空间转到屏幕空间。它还将每个顶点的数据传递到管道中。
细分着色器允许你根据某些规则对几何体进行细分以提高网格质量。这通常被用来使砖墙和楼梯等表面在附近时看起来不那么平。
几何着色器在每个基元(三角形、线、点)上运行,并可以丢弃它或输出比进来时更多的基元。这与镶嵌着色器类似,但要灵活得多。然而,它在今天的应用中用得不多,因为除了英特尔的集成GPU之外,大多数显卡的性能都不太理想。
栅格化阶段将基元离散成片段。这些是它们在帧缓冲器上填充的像素元素。任何落在屏幕外的片段都会被丢弃,顶点着色器输出的属性会在这些片段中进行插值,如图所示。通常情况下,由于深度测试的原因,位于其他基元片段后面的片段也会在这里被丢弃。
片段着色器对每一个幸存的片段都被调用,并决定片段被写入哪个(些)帧缓冲区,以及用哪个颜色和深度值。它可以使用来自顶点着色器的插值数据来做这件事,其中可以包括纹理坐标和法线等用于照明的东西。
颜色混合阶段应用操作来混合映射到帧缓冲区中同一像素的不同片段。片段可以简单地相互覆盖,增加或根据透明度进行混合。
带有绿色的阶段被称为固定功能阶段。这些阶段允许你使用参数来调整它们的操作,但它们的工作方式是预定义的。
另一方面,橙色的阶段是 “可编程”的,这意味着你可以上传你自己的代码到显卡,以精确地应用你想要的操作。例如,这允许你使用片段着色器来实现从纹理和照明到光线追踪的任何东西。这些程序同时在许多GPU核心上运行,以并行处理许多对象,如顶点和片段。
如果你以前使用过像OpenGL和Direct3D这样的旧API,那么你会习惯于通过glBlendFunc和OMSetBlendState这样的调用来随意改变任何管道设置。Vulkan的图形管道几乎是完全不可改变的,所以如果你想改变着色器、绑定不同的帧缓冲器或改变混合功能,你必须从头开始重新创建管道。其缺点是,你必须创建若干条管道,以代表你想在渲染操作中使用的所有不同的状态组合。然而,由于你要在管道中进行的所有操作都是事先知道的,因此驱动程序可以更好地进行优化。
一些可编程的阶段是可选的,基于你打算做什么。例如,如果你只是在绘制简单的几何图形,可以禁用细分化和几何阶段。如果你只对深度值感兴趣,那么你可以禁用片段着色器阶段,这对shadow map的生成很有用。
在下一章中,我们将首先创建将一个三角形放到屏幕上所需的两个可编程阶段:顶点着色器和片段着色器。固定功能的配置如混合模式、视口、光栅化将在之后的章节中设置。在Vulkan中设置图形管道的最后一部分涉及输入和输出帧缓冲器的规范。
创建一个createGraphicsPipeline函数,在initVulkan'中createImageViews`之后立即调用。我们将在接下来的章节中研究这个函数。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createGraphicsPipeline();
}
...
void createGraphicsPipeline() {
}着色器模块
与早期的API不同,Vulkan中的着色器代码必须以字节码格式指定,而不是像GLSL和HLSL那样的人类可读语法。这种字节码格式被称为SPIR-V,并被设计为同时用于Vulkan和OpenCL(都是Khronos API)。它是一种可以用来编写图形和计算着色器的格式,但在本教程中我们将专注于Vulkan的图形管道中使用的着色器。
使用字节码格式的好处是,由GPU供应商编写的将着色器代码转化为本地代码的编译器的复杂程度明显降低。过去的情况表明,对于像GLSL这样的人类可读语法,一些GPU供应商对标准的解释相当灵活。如果你碰巧用这些供应商之一的GPU编写了非琐碎的着色器,那么你将面临其他供应商的驱动程序由于语法错误而拒绝你的代码的风险,或者更糟的是,你的着色器由于编译器的错误而运行得不一样。有了像SPIR-V这样直接的字节码格式,就有希望避免这种情况了。
然而,这并不意味着我们需要手工编写这种字节码。Khronos已经发布了他们自己的独立于供应商的编译器,将GLSL编译为SPIR-V。这个编译器旨在验证你的着色器代码是否完全符合标准,并产生一个SPIR-V二进制文件,你可以和你的程序一起发送。你也可以把这个编译器作为一个库,在运行时产生SPIR-V,但我们在本教程中不会这样做。虽然我们可以通过glslangValidator.exe直接使用这个编译器,但我们将使用谷歌的glslc.exe来代替。glslc的优点是它使用与GCC和Clang等知名编译器相同的参数格式,并包括一些额外的功能,如includes。这两者都已经包含在Vulkan
SDK中,所以你不需要下载任何额外的东西。
GLSL是一种具有C风格语法的着色语言。用它编写的程序有一个main函数,每个对象都会被调用。GLSL使用全局变量来处理输入和输出,而不是使用参数作为输入,返回值作为输出。该语言包括许多帮助图形编程的功能,如内置矢量和矩阵基元。包括了一些操作的函数,如交叉积、矩阵-向量积和向量周围的反射。矢量类型被称为
vec,其中的数字表示元素的数量。例如,一个三维位置将被存储在
vec3
“中。可以通过像.x这样的成员来访问单个组件,但也可以同时从多个组件创建一个新的矢量。例如,表达式vec3(1.0, 2.0, 3.0).xy会产生vec2。向量的构造函数也可以接受向量对象和标量值的组合。例如,可以用vec3(vec2(1.0, 2.0), 3.0)构建一个vec3。
正如前一章所提到的,我们需要编写一个顶点着色器和一个片段着色器来在屏幕上获得一个三角形。接下来的两节将分别介绍其中的GLSL代码,之后我将向你展示如何制作两个SPIR-V二进制文件并将其加载到程序中。
顶点着色器
顶点着色器处理每个进入的顶点。它将其属性,如世界位置、颜色、法线和纹理坐标作为输入。输出是片段坐标的最终位置,以及需要传递给片段着色器的属性,如颜色和纹理坐标。然后,这些值将被光栅化器插值到片段上,以产生一个平滑的梯度。
夹点坐标是一个来自顶点着色器的四维向量,随后通过将整个向量除以其最后一个分量变成一个归一化设备坐标*。这些归一化设备坐标是齐次坐标,它将帧缓冲区映射到一个[-1, 1]乘[-1, 1]的坐标系中,看起来像下面这样:

如果你以前涉足过计算机图形,你应该已经熟悉这些了。如果你以前使用过OpenGL,那么你会注意到,Y坐标的符号现在被翻转了。Z坐标现在使用与Direct3D中相同的范围,从0到1。
对于我们的第一个三角形,我们不会应用任何变换,我们只是将三个顶点的位置直接指定为归一化设备坐标,以创建以下形状:

我们可以直接输出归一化的设备坐标,将它们作为顶点着色器的剪辑坐标输出,最后一个分量设置为`1’。这样一来,将剪辑坐标转换为归一化设备坐标的划分就不会有任何改变。
通常情况下,这些坐标会被存储在一个顶点缓冲区中,但是在Vulkan中创建一个顶点缓冲区并将数据填入其中并不是一件容易的事。因此,我决定将其推迟到我们看到屏幕上弹出一个三角形之后。与此同时,我们要做一些非正统的事情:直接在顶点着色器中包含坐标。这段代码看起来像这样:
#version 450
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
}main函数对每个顶点都会被调用。内置的gl_VertexIndex变量包含当前顶点的索引。这通常是顶点缓冲区的索引,但在我们的例子中,它将是一个硬编码的顶点数据数组的索引。每个顶点的位置被从着色器的常量数组中访问,并与假的z和w分量相结合,产生一个剪辑坐标的位置。内置变量gl_Position作为输出。
片段着色器
由顶点着色器的位置形成的三角形用片段填充屏幕上的一个区域。在这些片段上调用片段着色器以生成帧缓冲区(或多个帧缓冲区)的颜色和深度。为整个三角形输出红色的简单片段着色器如下所示:
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0, 0.0, 0.0, 1.0);
}main函数是为每个片段调用的,就像顶点着色器的main函数是为每个顶点调用的。GLSL中的颜色是4分量向量,R、G、B和alpha通道在[0,
1]范围内。与顶点着色器中的gl_Position不同,没有内置变量来输出当前片段的颜色。你必须为每个帧缓冲区指定你自己的输出变量,其中layout(location = 0)修改器指定帧缓冲区的索引。红色被写入这个
“outColor”变量,它与索引为0的第一个(也是唯一的)帧缓冲区相连接。
每个顶点的颜色
把整个三角形变成红色不是很有趣,像下面这样的渲染结果看起来不是更漂亮吗?
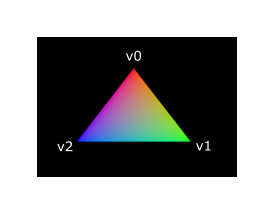
我们必须对这两个着色器做一些改变来实现这一点。首先,我们需要为三个顶点中的每个顶点指定一个不同的颜色。顶点着色器现在应该包括一个包含颜色的数组,就像它为位置所做的那样。
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);现在我们只需要将这些每个顶点的颜色传递给片段着色器,这样它就可以将它们的插值输出到帧缓冲区。为顶点着色器添加一个颜色输出,并在main函数中写入:
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}接下来,我们需要在片段着色器中添加一个匹配的输入:
layout(location = 0) in vec3 fragColor;
void main() {
outColor = vec4(fragColor, 1.0);
}输入变量不一定要使用相同的名字,它们将使用location指令指定的索引链接在一起。main函数已被修改,以输出颜色和一个alpha值。如上图所示,fragColor的值将自动对三个顶点之间的片段进行插值,从而形成一个平滑的梯度。
编译着色器
在你项目的根目录下创建一个名为 shaders
的目录,将顶点着色器存储在名为 shader.vert
的文件中,将片段着色器存储在名为 shader.frag
的文件中。GLSL着色器没有一个官方的扩展名,但这两个通常用来区分它们。
shader.vert的内容应该是:
#version 450
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}shader.frag的内容应该是:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}我们现在要用glslc程序将这些编译成SPIR-V字节码。
Windows
创建一个compile.bat文件,内容如下:
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.vert -o vert.spv
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.frag -o frag.spv
pause将glslc.exe的路径替换为你安装Vulkan
SDK的路径。双击该文件来运行它。
Linux
创建一个compile.sh文件,内容如下:
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.vert -o vert.spv
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.frag -o frag.spv将glslc的路径替换为你安装Vulkan
SDK的路径。用chmod +x compile.sh使脚本可执行并运行它。
平台特定指令结束
这两条命令告诉编译器读取GLSL源文件,并使用-o(输出)标志输出一个SPIR-V字节码文件。
如果你的着色器包含一个语法错误,那么编译器会告诉你行号和问题,正如你所期望的那样。试着把一个分号去掉,然后再次运行编译脚本。也可以尝试在没有任何参数的情况下运行编译器,看看它支持哪些类型的标志。例如,它还可以将字节码输出为人类可读的格式,这样你就可以看到你的着色器正在做什么,以及在这个阶段应用的任何优化。
在命令行上编译着色器是最直接的选择之一,这也是我们在本教程中要使用的选项,但也可以直接从自己的代码中编译着色器。Vulkan SDK包括libshaderc,它是一个库,可以在你的程序中把GLSL代码编译成SPIR-V。
加载一个着色器
现在我们已经有了制作SPIR-V着色器的方法,是时候把它们加载到我们的程序中,以便在某个时候把它们插入到图形管道中。我们首先要写一个简单的辅助函数,从文件中加载二进制数据。
#include <fstream>
...
static std::vector<char> readFile(const std::string& filename) {
std::ifstream file(filename, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
throw std::runtime_error("failed to open file!");
}
}readFile 函数将从指定的文件中读取所有的字节,并在一个由
std::vector管理的字节数组中返回这些字节。我们首先用两个标志打开文件。
ate: 从文件的末端开始读取binary: 将文件作为二进制文件读取(避免文本转换)
在文件末尾开始读取的好处是,我们可以使用读取位置来确定文件的大小并分配一个缓冲区:
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize);之后,我们可以寻回文件的开头,一次性读取所有的字节:
file.seekg(0);
file.read(buffer.data(), fileSize);最后关闭文件并返回字节。
file.close();
return buffer;现在我们将从createGraphicsPipeline中调用这个函数来加载两个着色器的字节码:
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
}通过打印缓冲区的大小并检查它们是否与实际的文件大小(字节)相符,确保着色器被正确加载。注意,代码不需要以空结束,因为它是二进制代码,我们以后会明确其大小。
创建着色器模块
在我们将代码传递给流水线之前,我们必须将其包裹在一个VkShaderModule对象中。让我们创建一个辅助函数createShaderModule来完成这个任务。
VkShaderModule createShaderModule(const std::vector<char>& code) {
}该函数将接收一个带有字节码的缓冲区作为参数,并从中创建一个VkShaderModule。
创建着色器模块很简单,我们只需要指定一个带有字节码的缓冲区的指针和它的长度。这些信息在一个VkShaderModuleCreateInfo结构中指定。有一个问题是字节码的大小是以字节为单位的,但是字节码的指针是一个uint32_t的指针,而不是char的指针。因此,我们需要用reinterpret_cast来铸造这个指针,如下图。当你执行这样的转换时,你还需要确保数据满足uint32_t的对齐要求。幸运的是,数据被存储在一个std::vector中,默认的分配器已经确保数据满足最坏情况下的对齐要求。
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = code.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data());然后可以通过调用vkCreateShaderModule来创建VkShaderModule。
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("failed to create shader module!");
}参数与之前对象创建函数中的参数相同:逻辑设备、创建信息结构的指针、自定义分配器的可选指针和处理输出变量。创建着色器模块后,带有代码的缓冲区可以立即被释放。不要忘记返回创建的着色器模块。
return shaderModule;着色器模块只是对我们之前从文件中加载的着色器字节码和其中定义的函数的一个简单的包装。SPIR-V字节码的编译和链接到机器代码,以便由GPU执行,这在图形管道创建之前不会发生。这意味着我们可以在管道创建完成后再次销毁着色器模块,这就是为什么我们要在createGraphicsPipeline函数中把它们变成局部变量而不是类成员:
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
VkShaderModule vertShaderModule = createShaderModule(vertShaderCode);
VkShaderModule fragShaderModule = createShaderModule(fragShaderCode);清理工作应该发生在函数的最后,通过添加两个对vkDestroyShaderModule的调用。本章中所有剩余的代码都将插入这些行之前。
...
vkDestroyShaderModule(device, fragShaderModule, nullptr);
vkDestroyShaderModule(device, vertShaderModule, nullptr);
}着色器阶段的创建
为了实际使用这些着色器,我们需要通过VkPipelineShaderStageCreateInfo结构将它们分配到一个特定的流水线阶段,作为实际流水线创建过程的一部分。
我们将首先填写顶点着色器的结构,还是在createGraphicsPipeline函数中。
VkPipelineShaderStageCreateInfo vertShaderStageInfo{};
vertShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
vertShaderStageInfo.stage = VK_SHADER_STAGE_VERTEX_BIT;除了必须的sType成员,第一步是告诉Vulkan着色器将在哪个管道阶段使用。在上一章中描述的每个可编程阶段都有一个枚举值。
vertShaderStageInfo.module = vertShaderModule;
vertShaderStageInfo.pName = "main";接下来的两个成员指定了包含代码的着色器模块,以及要调用的函数,称为entrypoint。这意味着可以将多个片段着色器合并到一个着色器模块中,并使用不同的入口点来区分它们的行为。然而,在这种情况下,我们将坚持使用标准的`main’。
还有一个(可选)成员,pSpecializationInfo,我们不会在这里使用,但值得讨论。它允许你为着色器常量指定数值。你可以使用一个单一的着色器模块,它的行为可以在管道创建时通过为其中使用的常量指定不同的值来进行配置。这比在渲染时使用变量来配置着色器更有效,因为编译器可以进行优化,比如消除依赖于这些值的if语句。如果你没有这样的常量,那么你可以将成员设置为nullptr,我们的结构初始化会自动这样做。
修改该结构以适应片段着色器是很容易的:
VkPipelineShaderStageCreateInfo fragShaderStageInfo{};
fragShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
fragShaderStageInfo.stage = VK_SHADER_STAGE_FRAGMENT_BIT;
fragShaderStageInfo.module = fragShaderModule;
fragShaderStageInfo.pName = "main";最后,定义一个包含这两个结构的数组,以后我们将在实际的管道创建步骤中用来引用它们。
VkPipelineShaderStageCreateInfo shaderStages[] = {vertShaderStageInfo, fragShaderStageInfo};这就是描述流水线的可编程阶段的全部内容。在下一章中,我们将看一下固定功能阶段。
C++ code / Vertex shader / Fragment shader
固定功能
旧的图形API为图形管道的大部分阶段提供了默认状态。在Vulkan中,你必须明确从视口大小到颜色混合功能的一切。在这一章中,我们将填入所有的结构来配置这些固定功能的操作。
顶点输入
VkPipelineVertexInputStateCreateInfo结构描述了将传递给顶点着色器的顶点数据的格式。它大致以两种方式描述。
- 绑定:数据之间的间距以及数据是逐顶点还是逐实例(参见 实例)
- 属性描述:传递给顶点着色器的属性的类型,从哪个绑定加载它们以及在哪个偏移量
因为我们直接在顶点着色器中对顶点数据进行了硬编码,所以我们将在这个结构中指定暂时没有顶点数据需要加载。我们将在顶点缓冲器一章中再讨论这个问题。
VkPipelineVertexInputStateCreateInfo vertexInputInfo{};
vertexInputInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO;
vertexInputInfo.vertexBindingDescriptionCount = 0;
vertexInputInfo.pVertexBindingDescriptions = nullptr; // Optional
vertexInputInfo.vertexAttributeDescriptionCount = 0;
vertexInputInfo.pVertexAttributeDescriptions = nullptr; // OptionalpVertexBindingDescriptions和pVertexAttributeDescriptions成员指向一个结构数组,描述上述加载顶点数据的细节。将此结构添加到createGraphicsPipeline函数中,紧随shaderStages数组之后。
输入装配
VkPipelineInputAssemblyStateCreateInfo结构描述了两件事:将从顶点绘制什么样的几何图形,以及是否应启用原始重启。前者是在topology成员中指定的,可以有以下值:
VK_PRIMITIVE_TOPOLOGY_POINT_LIST: 从顶点输入的点VK_PRIMITIVE_TOPOLOGY_LINE_LIST: 每2个顶点的线,不重复使用VK_PRIMITIVE_TOPOLOGY_LINE_STRIP: 每一行的结束顶点被用作下一行的起始顶点。VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST: 从每3个顶点出发的三角形,不重复使用VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP: 每个三角形的第二个和第三个顶点被用作下一个三角形的前两个顶点。
通常情况下,顶点是按索引顺序从顶点缓冲区加载的,但是有了元素缓冲区,你可以自己指定要使用的索引。这使你可以进行优化,比如重复使用顶点。如果你将primitiveRestartEnable成员设置为VK_TRUE,那么在_STRIP拓扑模式下,可以通过使用0xFFFF或0xFFFF的特殊索引来分解线条和三角形。
我们打算在本教程中一直画三角形,所以我们将坚持使用以下结构数据:
VkPipelineInputAssemblyStateCreateInfo inputAssembly{};
inputAssembly.sType = VK_STRUCTURE_TYPE_PIPELINE_INPUT_ASSEMBLY_STATE_CREATE_INFO;
inputAssembly.topology = VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST;
inputAssembly.primitiveRestartEnable = VK_FALSE;视口和剪切
视口基本上描述了输出将被渲染到的framebuffer的区域。这几乎总是(0,0)到(width, height),在本教程中也是如此。
VkViewport viewport{};
viewport.x = 0.0f;
viewport.y = 0.0f;
viewport.width = (float) swapChainExtent.width;
viewport.height = (float) swapChainExtent.height;
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;记住,交换链及其图像的大小可能与窗口的WIDTH和HEIGHT不同。交换链的图像以后将被用作帧缓冲器,所以我们应该坚持它们的尺寸。
minDepth和maxDepth值指定了用于帧缓冲区的深度值范围。这些值必须在[0.0f, 1.0f]范围内,但是minDepth可以高于maxDepth。如果你没有做什么特别的事情,那么你应该坚持使用0.0f'和1.0f’的标准值。
虽然视口定义了从图像到帧缓冲区的转换,但剪切矩形:定义了像素将被实际存储在哪些区域。剪切矩形之外的任何像素都会被光栅化器丢弃。它们的功能就像一个过滤器,而不是一个转换。区别如下图所示。请注意,左边的剪刀矩形只是产生该图像的众多可能性之一,只要它大于视口就可以了。
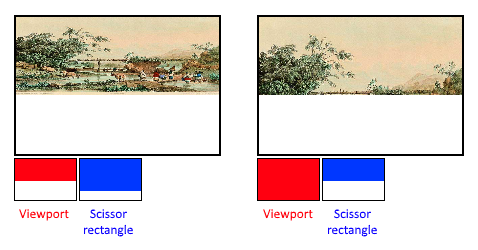
在本教程中,我们只想在整个帧缓冲区内作画,所以我们将指定一个完全覆盖它的剪切矩形:
VkRect2D scissor{};
scissor.offset = {0, 0};
scissor.extent = swapChainExtent;现在需要使用VkPipelineViewportStateCreateInfo结构将这个视口和剪切形矩形组合成一个视口状态。在某些显卡上可以使用多个视口和剪切矩形,所以它的成员引用了它们的数组。使用多个需要启用GPU功能(见逻辑设备创建)。
VkPipelineViewportStateCreateInfo viewportState{};
viewportState.sType = VK_STRUCTURE_TYPE_PIPELINE_VIEWPORT_STATE_CREATE_INFO;
viewportState.viewportCount = 1;
viewportState.pViewports = &viewport;
viewportState.scissorCount = 1;
viewportState.pScissors = &scissor;光栅化
光栅化从顶点着色器中获取由顶点塑造的几何体,并将其转化为片段,由片段着色器进行着色。它还执行depth testing、face
culling和scissor
test,并且它可以被配置为输出填充整个多边形或仅填充边缘的片段(wireframe
rendering)。所有这些都是通过VkPipelineRasterizationStateCreateInfo结构配置的。
VkPipelineRasterizationStateCreateInfo rasterizer{};
rasterizer.sType = VK_STRUCTURE_TYPE_PIPELINE_RASTERIZATION_STATE_CREATE_INFO;
rasterizer.depthClampEnable = VK_FALSE;如果depthClampEnable被设置为VK_TRUE,那么超出近平面和远平面的片段会被夹住,而不是丢弃。这在一些特殊情况下是很有用的,比如阴影图。使用这个需要启用一个GPU功能。
rasterizer.rasterizerDiscardEnable = VK_FALSE;如果rasterizerDiscardEnable被设置为VK_TRUE,那么几何体就不会通过光栅化器阶段。这基本上是禁用任何输出到帧缓冲区的功能。
rasterizer.polygonMode = VK_POLYGON_MODE_FILL;polygonMode
决定了如何生成几何体的片段。有以下模式可供选择。
VK_POLYGON_MODE_FILL:用片段填充多边形的区域。VK_POLYGON_MODE_LINE:多边形的边缘被绘制成线。VK_POLYGON_MODE_POINT:多边形顶点被画成点。
使用填充以外的任何模式需要启用GPU功能。
rasterizer.lineWidth = 1.0f;lineWidth成员很直接,它以片段的数量来描述线条的厚度。支持的最大线宽取决于硬件,任何比1.0f厚的线都需要你启用wideLinesGPU功能。
rasterizer.cullMode = VK_CULL_MODE_BACK_BIT;
rasterizer.frontFace = VK_FRONT_FACE_CLOCKWISE;cullMode
变量确定要使用的面剔除类型。您可以禁用剔除、剔除正面、剔除背面或两者。
frontFace
变量指定被视为正面的面的顶点顺序,可以是顺时针或逆时针。
rasterizer.depthBiasEnable = VK_FALSE;
rasterizer.depthBiasConstantFactor = 0.0f; // Optional
rasterizer.depthBiasClamp = 0.0f; // Optional
rasterizer.depthBiasSlopeFactor = 0.0f; // Optional栅格化器可以通过添加一个常量值或根据片段的斜率对其进行偏置来改变深度值。这有时用于阴影贴图,但我们不会使用它。只要将depthBiasEnable设置为VK_FALSE即可。
多重采样
VkPipelineMultisampleStateCreateInfo结构配置了多重采样,这是执行抗锯齿的方法之一。它的工作原理是将光栅化为同一像素的多个多边形的片段着色器结果结合在一起。这主要是沿着边缘发生的,这也是最明显的混叠伪影发生的地方。因为如果只有一个多边形映射到一个像素,它就不需要多次运行片段着色器,这比简单地渲染到一个更高的分辨率然后降频的成本要低很多。启用它需要启用一个GPU功能。
VkPipelineMultisampleStateCreateInfo multisampling{};
multisampling.sType = VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO;
multisampling.sampleShadingEnable = VK_FALSE;
multisampling.rasterizationSamples = VK_SAMPLE_COUNT_1_BIT;
multisampling.minSampleShading = 1.0f; // Optional
multisampling.pSampleMask = nullptr; // Optional
multisampling.alphaToCoverageEnable = VK_FALSE; // Optional
multisampling.alphaToOneEnable = VK_FALSE; // Optional我们将在后面的章节中重新讨论多重采样的问题,现在让我们把它关闭。
深度和模版测试
如果你使用深度和/或钢网缓冲器,那么你还需要使用VkPipelineDepthStencilStateCreateInfo配置深度和钢网测试。我们现在没有,所以我们可以简单地传递一个nullptr,而不是指向这样一个结构的指针。我们将在深度缓冲章节中再讨论这个问题。
颜色混合
在片段着色器返回颜色后,需要将其与已经存在于帧缓冲器中的颜色结合起来。这种转换被称为颜色混合,有两种方法可以做到这一点。
- 将新旧值混合,产生最终的颜色
- 使用位操作将新旧值结合起来
有两种类型的结构可以配置颜色混合。第一个结构,VkPipelineColorBlendAttachmentState包含每个附加帧缓冲区的配置,第二个结构,VkPipelineColorBlendStateCreateInfo包含全球颜色混合设置。在我们的例子中,我们只有一个帧缓冲器。
VkPipelineColorBlendAttachmentState colorBlendAttachment{};
colorBlendAttachment.colorWriteMask = VK_COLOR_COMPONENT_R_BIT | VK_COLOR_COMPONENT_G_BIT | VK_COLOR_COMPONENT_B_BIT | VK_COLOR_COMPONENT_A_BIT;
colorBlendAttachment.blendEnable = VK_FALSE;
colorBlendAttachment.srcColorBlendFactor = VK_BLEND_FACTOR_ONE; // Optional
colorBlendAttachment.dstColorBlendFactor = VK_BLEND_FACTOR_ZERO; // Optional
colorBlendAttachment.colorBlendOp = VK_BLEND_OP_ADD; // Optional
colorBlendAttachment.srcAlphaBlendFactor = VK_BLEND_FACTOR_ONE; // Optional
colorBlendAttachment.dstAlphaBlendFactor = VK_BLEND_FACTOR_ZERO; // Optional
colorBlendAttachment.alphaBlendOp = VK_BLEND_OP_ADD; // Optional这个每帧缓冲区结构允许你配置颜色混合的第一种方式。将要进行的操作最好用下面的伪代码来演示:
if (blendEnable) {
finalColor.rgb = (srcColorBlendFactor * newColor.rgb) <colorBlendOp> (dstColorBlendFactor * oldColor.rgb);
finalColor.a = (srcAlphaBlendFactor * newColor.a) <alphaBlendOp> (dstAlphaBlendFactor * oldColor.a);
} else {
finalColor = newColor;
}
finalColor = finalColor & colorWriteMask;如果blendEnable被设置为VK_FALSE,那么来自片段着色器的新颜色就会不加修改地通过。否则,两个混合操作将被执行以计算出一个新的颜色。得到的颜色与
“colorWriteMask”相乘,以确定哪些通道实际被通过。
使用颜色混合的最常见方式是实现alpha混合,我们希望新的颜色与旧的颜色根据其不透明度进行混合。然后,“最终颜色”应按以下方式计算:
finalColor.rgb = newAlpha * newColor + (1 - newAlpha) * oldColor;
finalColor.a = newAlpha.a;这可以通过以下参数来实现:
colorBlendAttachment.blendEnable = VK_TRUE;
colorBlendAttachment.srcColorBlendFactor = VK_BLEND_FACTOR_SRC_ALPHA;
colorBlendAttachment.dstColorBlendFactor = VK_BLEND_FACTOR_ONE_MINUS_SRC_ALPHA;
colorBlendAttachment.colorBlendOp = VK_BLEND_OP_ADD;
colorBlendAttachment.srcAlphaBlendFactor = VK_BLEND_FACTOR_ONE;
colorBlendAttachment.dstAlphaBlendFactor = VK_BLEND_FACTOR_ZERO;
colorBlendAttachment.alphaBlendOp = VK_BLEND_OP_ADD;你可以在规范中的VkBlendFactor和VkBlendOp枚举中找到所有的可能操作。
第二个结构引用了所有帧缓冲器的结构数组,并允许你设置混合常数,你可以在上述计算中作为混合系数使用。
VkPipelineColorBlendStateCreateInfo colorBlending{};
colorBlending.sType = VK_STRUCTURE_TYPE_PIPELINE_COLOR_BLEND_STATE_CREATE_INFO;
colorBlending.logicOpEnable = VK_FALSE;
colorBlending.logicOp = VK_LOGIC_OP_COPY; // Optional
colorBlending.attachmentCount = 1;
colorBlending.pAttachments = &colorBlendAttachment;
colorBlending.blendConstants[0] = 0.0f; // Optional
colorBlending.blendConstants[1] = 0.0f; // Optional
colorBlending.blendConstants[2] = 0.0f; // Optional
colorBlending.blendConstants[3] = 0.0f; // Optional如果你想使用第二种混合方法(逐位组合),那么你应该把logicOpEnable设置为VK_TRUE。然后可以在logicOp字段中指定位操作。请注意,这将自动禁用第一个方法,就像你为每个连接的帧缓冲器设置blendEnable为VK_FALSE一样!
在这种模式下,colorWriteMask也将被用来确定帧缓冲器中的哪些通道将被实际影响。也可以禁用这两种模式,就像我们在这里做的那样,在这种情况下,片段的颜色将被写入帧缓冲区而不被修改。
动态状态
我们在前面的结构中指定的有限数量的状态可以在不重新创建管道的情况下实际改变。例如,视口的大小、线宽和混合常数。如果你想这样做,那么你必须填写一个VkPipelineDynamicStateCreateInfo结构,像这样:
std::vector<VkDynamicState> dynamicStates = {
VK_DYNAMIC_STATE_VIEWPORT,
VK_DYNAMIC_STATE_LINE_WIDTH
};
VkPipelineDynamicStateCreateInfo dynamicState{};
dynamicState.sType = VK_STRUCTURE_TYPE_PIPELINE_DYNAMIC_STATE_CREATE_INFO;
dynamicState.dynamicStateCount = static_cast<uint32_t>(dynamicStates.size());
dynamicState.pDynamicStates = dynamicStates.data();这将导致这些值的配置被忽略,你将被要求在绘图时指定数据。我们将在以后的章节中再讨论这个问题。如果你没有任何动态状态,这个结构以后可以用nullptr来代替。
管线布局
你可以在着色器中使用uniform值,它是类似于动态状态变量的球状物,可以在绘制时改变,以改变着色器的行为,而不必重新创建它们。它们通常被用来向顶点着色器传递变换矩阵,或者在片段着色器中创建纹理采样器。
这些统一的值需要在创建管道时通过创建一个VkPipelineLayout对象来指定。尽管我们在未来的章节中才会使用它们,但我们仍然需要创建一个空的管道布局。
创建一个类成员来保存这个对象,因为我们会在以后的时间点从其他函数中引用它:
VkPipelineLayout pipelineLayout;然后在createGraphicsPipeline函数中创建该对象:
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 0; // Optional
pipelineLayoutInfo.pSetLayouts = nullptr; // Optional
pipelineLayoutInfo.pushConstantRangeCount = 0; // Optional
pipelineLayoutInfo.pPushConstantRanges = nullptr; // Optional
if (vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &pipelineLayout) != VK_SUCCESS) {
throw std::runtime_error("failed to create pipeline layout!");
}该结构还指定了push常量,这是另外一种向着色器传递动态值的方式,我们可能会在以后的章节中讨论。管道布局将在整个程序的生命周期中被引用,所以它应该在最后被销毁:
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}结论
所有的固定功能状态就这样了! 从头开始设置所有这些是一个很大的工作,但好处是我们现在几乎完全知道图形管道中正在进行的所有事情!这减少了由于某些组件的默认状态与你所期望的不同而遇到意外行为的机会。这就减少了因为某些组件的默认状态与你所期望的不同而遇到意外行为的机会。
然而,在我们最终创建图形管道之前,还有一个对象需要创建,那就是渲染通道。
C++ code / Vertex shader / Fragment shader
渲染通道
开始
在我们完成创建管道之前,我们需要告诉Vulkan渲染时将使用的帧缓冲器附件。我们需要指定有多少个颜色和深度缓冲区,每个缓冲区要使用多少个样本,以及在整个渲染操作中如何处理它们的内容。所有这些信息都被包裹在一个渲染通道对象中,我们将为它创建一个新的createRenderPass函数。在createGraphicsPipeline之前从inVulkan调用这个函数。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
}
...
void createRenderPass() {
}附件描述
在我们的例子中,我们将只有一个单一的颜色缓冲区附件,由交换链中的一个图像代表。
void createRenderPass() {
VkAttachmentDescription colorAttachment{};
colorAttachment.format = swapChainImageFormat;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
}颜色附件的format应该与交换链图像的格式相匹配,我们还没有做任何多采样的事情,所以我们将坚持使用一个样本。
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
colorAttachment.storeOp = VK_ATTACHMENT_STORE_OP_STORE;loadOp和storeOp决定在渲染前和渲染后如何处理附件中的数据。我们对loadOp有以下选择。
vk_attachment_load_op_load: 保留附件中的现有内容vk_attachment_load_op_clear: 在开始时清除数值到一个常数vk_attachment_load_op_dont_care: 现有的内容是未定义的;我们不关心它们
在我们的例子中,我们要使用清除操作,在绘制新帧之前将帧缓冲区清除为黑色。storeOp只有两种可能性。
vk_attachment_store_op_store:渲染的内容将被保存在内存中,以后可以被读取vk_attachment_store_op_dont_care: 渲染操作后,帧缓冲区的内容将不被定义。
我们感兴趣的是在屏幕上看到渲染后的三角形,所以我们在这里采用存储操作。
colorAttachment.stencilLoadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
colorAttachment.stencilStoreOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;loadOp 和 storeOp
适用于颜色和深度数据,stencilLoadOp /
stencilStoreOp
适用于模板数据。我们的应用程序不会对模板缓冲区做任何事情,因此加载和存储的结果是无关紧要的。
colorAttachment.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
colorAttachment.finalLayout = VK_IMAGE_LAYOUT_PRESENT_SRC_KHR;Vulkan 中的纹理和帧缓冲区由具有特定像素格式的 VkImage
对象表示,但是布局内存中的像素可以根据您尝试对图像执行的操作而改变。
一些最常见的布局是:
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL:用作颜色附件的图像VK_IMAGE_LAYOUT_PRESENT_SRC_KHR:要在交换链中呈现的图像VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL:用作内存复制操作目标的图像
我们将在纹理化章节中更深入地讨论这个主题,但现在重要的是要知道图像需要转换为适合它们接下来将涉及的操作的特定布局。
initialLayout 指定在渲染过程开始之前图像将具有的布局。
finalLayout 指定渲染过程完成时自动转换到的布局。为
initialLayout 使用 VK_IMAGE_LAYOUT_UNDEFINED
意味着我们不关心图像之前的布局。这个特殊值的警告是图像的内容不能保证被保留,但这并不重要,因为无论如何,我们都会清除它。我们希望图像在渲染后使用交换链准备好呈现,这就是我们使用VK_IMAGE_LAYOUT_PRESENT_SRC_KHR作为finalLayout的原因。
子通道和引用附件
一个渲染通道可以由多个子通道组成。子通道是依赖于之前通道中帧缓冲区内容的后续渲染操作,例如,一连串的后期处理效果被相继应用。如果你将这些渲染操作归入一个渲染通道,那么Vulkan就能够重新安排这些操作的顺序,并节省内存带宽,从而可能获得更好的性能。然而,对于我们的第一个三角形,我们将坚持使用单一的子通道。
每个子通道都会引用一个或多个我们在前面章节中使用结构描述的附件。这些引用本身是VkAttachmentReference
结构,看起来像这样。
VkAttachmentReference colorAttachmentRef{};
colorAttachmentRef.attachment = 0;
colorAttachmentRef.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;attachment参数通过附件描述数组中的索引指定要引用的附件。我们的数组由一个VkAttachmentDescription组成,所以其索引是0。layout指定了我们希望附件在使用该引用的子通道中拥有的布局。当子通道开始时,Vulkan会自动将附件过渡到这个布局。我们打算使用附件作为一个颜色缓冲器,VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL布局将给我们带来最好的性能,正如其名称所暗示的那样。
子通道使用VkSubpassDescription结构来描述:
VkSubpassDescription subpass{};
subpass.pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;Vulkan在未来可能也会支持计算子通道,所以我们必须明确指出这是一个图形子通道。接下来,我们指定对颜色附件的引用:
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &colorAttachmentRef;这个数组中附件的索引是通过layout(location = 0) out vec4 outColor指令从片段着色器中直接引用的
以下其他类型的附件可以被子通道引用。
pInputAttachments:从着色器中读取的附件pResolveAttachments: 用于多重取样的颜色附件pDepthStencilAttachment: 用于深度和模版数据的附件pPreserveAttachments: 该子通道不使用的附件,但必须保留其数据的附件
渲染通道
现在,附件和引用它的基本子通道已经被描述了,我们可以创建渲染通道本身。创建一个新的类成员变量来保存VkRenderPass对象,就在pipelineLayout变量上面:
VkRenderPass renderPass;
VkPipelineLayout pipelineLayout;然后可以通过在VkRenderPassCreateInfo结构中填写附件和子通道的数组来创建渲染通道对象。VkAttachmentReference对象使用这个数组的索引引用附件。
VkRenderPassCreateInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
renderPassInfo.attachmentCount = 1;
renderPassInfo.pAttachments = &colorAttachment;
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
if (vkCreateRenderPass(device, &renderPassInfo, nullptr, &renderPass) != VK_SUCCESS) {
throw std::runtime_error("failed to create render pass!");
}就像管道布局一样,渲染通道将在整个程序中被引用,所以它应该在最后才被清理掉:
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
vkDestroyRenderPass(device, renderPass, nullptr);
...
}这是一项大量的工作,但在下一章中,所有的工作都汇集在一起,最终创建了图形管道对象!这就是我们的工作。
C++ code / Vertex shader / Fragment shader
结论
我们现在可以把前几章中的所有结构和对象结合起来,创建图形管道了!这就是我们现在拥有的对象的类型。下面是我们现在拥有的对象的类型,作为快速回顾。
- 着色器阶段:定义图形管道可编程阶段功能的着色器模块。
- 固定功能状态:定义流水线固定功能阶段的所有结构,如输入组件、光栅化器、视口和颜色混合等
- 管道布局:着色器所引用的统一和推送值,可以在绘制时进行更新
- 渲染通道:流水线阶段所引用的附件及其使用。
所有这些结合起来完全定义了图形管道的功能,所以我们现在可以开始在
createGraphicsPipeline函数的最后填写VkGraphicsPipelineCreateInfo结构。但是在调用vkDestroyShaderModule之前,因为这些仍然要在创建期间使用。
VkGraphicsPipelineCreateInfo pipelineInfo{};
pipelineInfo.sType = VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO;
pipelineInfo.stageCount = 2;
pipelineInfo.pStages = shaderStages;我们首先引用VkPipelineShaderStageCreateInfo结构的阵列。
pipelineInfo.pVertexInputState = &vertexInputInfo;
pipelineInfo.pInputAssemblyState = &inputAssembly;
pipelineInfo.pViewportState = &viewportState;
pipelineInfo.pRasterizationState = &rasterizer;
pipelineInfo.pMultisampleState = &multisampling;
pipelineInfo.pDepthStencilState = nullptr; // Optional
pipelineInfo.pColorBlendState = &colorBlending;
pipelineInfo.pDynamicState = nullptr; // Optional然后我们引用所有描述固定功能阶段的结构。
pipelineInfo.layout = pipelineLayout;之后是管道布局,它是一个Vulkan句柄而不是一个结构指针。
pipelineInfo.renderPass = renderPass;
pipelineInfo.subpass = 0;最后,我们有对渲染通道的引用和子通道的索引,这个图形管道将被使用。我们也可以使用其他渲染通道来代替这个特定的实例,但它们必须与renderPass兼容。兼容性的要求在这里有描述,但我们不会在本教程中使用这一功能。
pipelineInfo.basePipelineHandle = VK_NULL_HANDLE; // Optional
pipelineInfo.basePipelineIndex = -1; // Optional实际上还有两个参数。basePipelineHandle和basePipelineIndex。Vulkan允许你通过衍生现有的管道来创建一个新的图形管道。管线派生的想法是,当管线与现有管线有很多共同的功能时,建立管线的成本较低,在同一父管线之间的切换也可以更快完成。你可以用basePipelineHandle指定一个现有管道的句柄,或者用basePipelineIndex引用另一个即将创建的管道的索引。现在只有一个管道,所以我们将简单地指定一个空手柄和一个无效的索引。只有在VkGraphicsPipelineCreateInfo的flags字段中也指定了VK_PIPELINE_CREATE_DERIVATIVE_BIT标志时才会使用这些值。
现在为最后一步做准备,创建一个类成员来容纳VkPipeline
对象:
VkPipeline graphicsPipeline;最后创建图形管道:
if (vkCreateGraphicsPipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &graphicsPipeline) != VK_SUCCESS) {
throw std::runtime_error("failed to create graphics pipeline!");
}vkCreateGraphicsPipelines函数实际上比Vulkan中通常的对象创建函数有更多参数。它被设计用来接收多个VkGraphicsPipelineCreateInfo对象并在一次调用中创建多个VkPipeline对象。
第二个参数,我们为其传递了VK_NULL_HANDLE参数,引用了一个可选的VkPipelineCache对象。管线缓存可以用来存储和重用与管线创建相关的数据,跨越对vkCreateGraphicsPipelines的多次调用,如果缓存被存储到文件中,甚至跨越程序执行。这使得我们有可能在以后的时间里大大加快管道的创建速度。我们将在管线缓存一章中讨论这个问题。
图形管道对于所有常见的绘图操作都是必需的,所以它也应该只在程序结束时被销毁。
void cleanup() {
vkDestroyPipeline(device, graphicsPipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}现在运行你的程序,以确认所有这些努力工作的结果是成功地创建了一个管道! 我们已经很接近看到屏幕上出现的东西了。在接下来的几章中,我们将从交换链图像中设置实际的帧缓冲器,并准备好绘图命令。
C++ code / Vertex shader / Fragment shader
绘制
帧缓冲区
在过去的几章中,我们已经谈了很多关于帧缓冲的内容,我们已经将渲染传递设置为期望一个与交换链图像格式相同的单一帧缓冲,但我们还没有实际创建任何图像。
渲染通道创建过程中指定的附件是通过将它们包装成一个VkFramebuffer对象来绑定的。一个framebuffer对象引用所有代表附件的VkImageView对象。在我们的例子中,这将是唯一的一个:颜色附件。然而,我们必须为附件使用的图像取决于当我们检索到一个用于展示的图像时,交换链会返回哪一个。这意味着我们必须为交换链中的所有图像创建一个帧缓冲区,并在绘图时使用与检索到的图像相对应的那个。
为此,创建另一个std::vector类成员来保存帧缓冲区。
std::vector<VkFramebuffer> swapChainFramebuffers;我们将在一个新的函数createFramebuffers中为这个数组创建对象,该函数在创建图形管道后立即从initVulkan中调用:
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}
...
void createFramebuffers() {
}首先调整容器的大小以容纳所有的帧缓冲区:
void createFramebuffers() {
swapChainFramebuffers.resize(swapChainImageViews.size());
}然后我们将遍历图像视图,并从中创建帧缓冲区:
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
VkImageView attachments[] = {
swapChainImageViews[i]
};
VkFramebufferCreateInfo framebufferInfo{};
framebufferInfo.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO;
framebufferInfo.renderPass = renderPass;
framebufferInfo.attachmentCount = 1;
framebufferInfo.pAttachments = attachments;
framebufferInfo.width = swapChainExtent.width;
framebufferInfo.height = swapChainExtent.height;
framebufferInfo.layers = 1;
if (vkCreateFramebuffer(device, &framebufferInfo, nullptr, &swapChainFramebuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create framebuffer!");
}
}正如你所看到的,创建framebuffers是非常直接的。我们首先需要指定帧缓冲器需要与哪个 “renderPass”兼容。你只能将一个framebuffer与它所兼容的渲染通道一起使用,这大概意味着它们使用相同数量和类型的附件。
attachmentCount和pAttachments参数指定了VkImageView对象,这些对象应该被绑定到渲染通道pAttachment数组中各自的附件描述。
width和height参数是不言而喻的,layers指的是图像阵列中的层数。我们的交换链图像是单个图像,所以层数是1。
我们应该在图像视图和它们所基于的渲染传递之前删除帧缓冲器,但只有在我们完成渲染之后:
void cleanup() {
for (auto framebuffer : swapChainFramebuffers) {
vkDestroyFramebuffer(device, framebuffer, nullptr);
}
...
}我们现在已经达到了一个里程碑,即我们拥有了渲染所需的所有对象。在下一章中,我们将编写第一个实际的绘图命令。
C++ code / Vertex shader / Fragment shader
命令缓冲区
Vulkan中的命令,如绘图操作和内存传输,不能直接使用函数调用执行。你必须在命令缓冲区对象中记录你想要执行的所有操作。这样做的好处是,当我们准备告诉Vulkan我们想要做什么的时候,所有的命令都会一起提交,Vulkan可以更有效地处理这些命令,因为所有的命令都可以一起使用。此外,如果需要的话,这允许命令记录在多个线程中发生。
命令池
在创建命令缓冲区之前,我们必须先创建一个命令池。命令池管理用于存储缓冲区的内存,而命令缓冲区是由它们分配的。添加一个新的类成员来存储一个VkCommandPool:
VkCommandPool commandPool;然后创建一个新的函数createCommandPool并在帧缓冲器创建后从initVulkan调用它。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
}
...
void createCommandPool() {
}命令池的创建只需要两个参数:
QueueFamilyIndices queueFamilyIndices = findQueueFamilies(physicalDevice);
VkCommandPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
poolInfo.flags = VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT;
poolInfo.queueFamilyIndex = queueFamilyIndices.graphicsFamily.value();命令池有两个可能的Flag:
vk_command_pool_create_transient_bit。提示命令缓冲区经常被新的命令重新记录(可能会改变内存分配行为)vk_command_pool_create_reset_command_buffer_bit: 允许命令缓冲区单独被重新记录,如果没有这个标志,它们就必须一起被重置。
我们将在每一帧记录一个命令缓冲区,所以我们希望能够在它上面重置和重新记录。因此,我们需要为我们的命令池设置VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT标志位。
命令缓冲区是通过在一个设备队列中提交来执行的,就像我们检索到的图形和演示队列一样。每个命令池只能分配在单一类型队列上提交的命令缓冲区。我们要记录绘图的命令,这就是我们选择图形队列系列的原因。
if (vkCreateCommandPool(device, &poolInfo, nullptr, &commandPool) != VK_SUCCESS) {
throw std::runtime_error("failed to create command pool!");
}使用vkCreateCommandPool函数完成创建命令池。它没有任何特殊参数。命令将在整个程序中被用来在屏幕上画东西,所以这个池子应该只在最后被销毁:
void cleanup() {
vkDestroyCommandPool(device, commandPool, nullptr);
...
}命令缓冲区分配
我们现在可以开始分配命令缓冲区了。
创建一个VkCommandBuffer对象作为一个类成员。命令缓冲区将在其命令池被销毁时自动释放,所以我们不需要显式清理。
VkCommandBuffer commandBuffer;我们现在开始研究createCommandBuffer函数,从命令池中分配一个命令缓冲区。
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffer();
}
...
void createCommandBuffer() {
}命令缓冲区是用vkAllocateCommandBuffers函数分配的,该函数接收一个VkCommandBufferAllocateInfo结构作为参数,指定要分配的命令池和缓冲区的数量:
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
allocInfo.commandBufferCount = 1;
if (vkAllocateCommandBuffers(device, &allocInfo, &commandBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate command buffers!");
}level参数指定分配的命令缓冲区是主命令缓冲区还是次要命令缓冲区。
vk_command_buffer_level_primary: 可以提交到队列中执行,但不能从其他命令缓冲区调用。vk_command_buffer_level_secondary: 不能直接提交,但可以从初级命令缓冲区调用。
我们不会在这里使用二级命令缓冲区的功能,但你可以想象,重用一级命令缓冲区的常用操作是很有帮助的。
因为我们只分配一个命令缓冲区,所以commandBufferCount参数只有一个。
命令缓冲区记录
我们现在开始研究recordCommandBuffer函数,它将我们想要执行的命令写入一个命令缓冲区。使用的VkCommandBuffer将作为参数传入,以及我们想写到的当前交换链图像的索引。
void recordCommandBuffer(VkCommandBuffer commandBuffer, uint32_t imageIndex) {
}我们总是通过调用vkBeginCommandBuffer来开始记录一个命令缓冲区,并以一个小的VkCommandBufferBeginInfo结构作为参数,指定关于这个特定命令缓冲区使用的一些细节。
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = 0; // Optional
beginInfo.pInheritanceInfo = nullptr; // Optional
if (vkBeginCommandBuffer(commandBuffer, &beginInfo) != VK_SUCCESS) {
throw std::runtime_error("failed to begin recording command buffer!");
}参数flags指定了我们将如何使用命令缓冲区。以下是可用的值。
vk_command_buffer_usage_one_time_submit_bit: 命令缓冲区在执行一次后将被立即重新记录。vk_command_buffer_usage_render_pass_continue_bit: 这是一个次要的命令缓冲区,将完全在一个渲染通道内进行。vk_command_buffer_usage_simultaneous_use_bit: 命令缓冲区可以重新提交,同时它也已经在等待执行。
这些标志现在对我们都不适用。
pInheritanceInfo参数只与二级命令缓冲区有关。它指定从调用的主命令缓冲区继承哪个状态。
如果命令缓冲区已经被记录过一次,那么调用vkBeginCommandBuffer将隐含地重置它。在以后的时间里,不可能再向缓冲区追加命令。
开始一个渲染通道
绘制开始于使用vkCmdBeginRenderPass开始渲染通道。渲染通道是使用VkRenderPassBeginInfo结构中的一些参数来配置的。
VkRenderPassBeginInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
renderPassInfo.renderPass = renderPass;
renderPassInfo.framebuffer = swapChainFramebuffers[imageIndex];第一个参数是渲染通道本身和要绑定的附件。我们为每个交换链图像创建了一个framebuffer,它被指定为一个颜色附件。因此,我们需要为我们想要绘制的交换链图像绑定帧缓冲器。使用传入的imageIndex参数,我们可以为当前交换链图像选择正确的帧缓冲区。
renderPassInfo.renderArea.offset = {0, 0};
renderPassInfo.renderArea.extent = swapChainExtent;接下来的两个参数定义了渲染区的大小。渲染区域定义了着色器的加载和存储将在哪里进行。这个区域之外的像素将有未定义的值。它应该与附件的大小相匹配以获得最佳性能。
VkClearValue clearColor = {{{0.0f, 0.0f, 0.0f, 1.0f}}};
renderPassInfo.clearValueCount = 1;
renderPassInfo.pClearValues = &clearColor;最后两个参数定义了用于VK_ATTACHMENT_LOAD_OP_CLEAR的透明值,我们用它作为颜色附件的加载操作。我把透明色定义为简单的黑色,不透明度为100%。
vkCmdBeginRenderPass(commandBuffer, &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);现在可以开始渲染通道了。所有记录命令的函数都可以通过其vkCmd前缀来识别。它们都返回void,所以在我们完成记录之前不会有任何错误处理。
每个命令的第一个参数都是要记录的命令缓冲区。第二个参数指定我们刚刚提供的渲染通道的细节。最后一个参数控制渲染通道中的绘图命令的提供方式。它可以有两个值之一。
vk_subpass_contents_inline。渲染通道的命令将被嵌入到主命令缓冲区本身,不会执行次要命令缓冲区。vk_subpass_contents_secondary_command_buffers: 渲染通道的命令将从二级命令缓冲区执行。
我们不会使用二级命令缓冲区,所以我们会选择第一个选项。
基本绘制命令
我们现在可以绑定图形管道:
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);第二个参数指定管线对象是图形管线还是计算管线。我们现在已经告诉Vulkan哪些操作要在图形管道中执行,哪些附件要在片段着色器中使用,所以剩下的就是告诉它要绘制三角形:
vkCmdDraw(commandBuffer, 3, 1, 0, 0);实际的vkCmdDraw函数有点反常,但它如此简单是因为我们事先指定了所有信息。除了命令缓冲区外,它有以下参数。
vertexCount:尽管我们没有顶点缓冲区,但从技术上讲,我们仍然有3个顶点需要绘制。instanceCount: 用于实例渲染,如果你不这样做,使用`1’。firstVertex: 用作顶点缓冲区的偏移量,定义了gl_VertexIndex的最低值。firstInstance: 用作实例渲染的偏移量,定义了gl_InstanceIndex的最低值。
结束
现在可以结束渲染通道:
vkCmdEndRenderPass(commandBuffer);而我们已经完成了记录命令缓冲区:
if (vkEndCommandBuffer(commandBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to record command buffer!");
}在下一章,我们将编写主循环的代码,它将从交换链中获取一个图像,记录并执行一个命令缓冲区,然后将完成的图像返回到交换链中。
C++ code / Vertex shader / Fragment shader
渲染和展示
在这一章中,所有的东西都将被整合到一起。我们将编写drawFrame函数,从主循环中调用,将三角形放在屏幕上。让我们开始创建这个函数,并从mainLoop中调用它:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}
...
void drawFrame() {
}渲染一帧概述
在高层次上,在Vulkan中渲染一帧由一组共同的步骤组成。
- 等待前一帧的完成
- 从交换链中获取一个图像
- 记录一个命令缓冲区,将场景绘制到该图像上
- 提交记录的命令缓冲区
- 呈现交换链的图像
虽然我们将在后面的章节中扩展绘图功能,但现在这就是我们渲染循环的核心。
同步
Vulkan的一个核心设计理念是,在GPU上执行的同步是明确的。操作的顺序是由我们使用各种同步原语来定义的,这些原语告诉驱动程序我们希望事情的运行顺序。这意味着许多在GPU上开始执行工作的Vulkan API调用是异步的,这些函数将在操作完成之前返回。
在本章中,有一些事件我们需要明确排序,因为它们发生在GPU上,比如。
- 从交换链中获取一个图像
- 执行在获取的图像上绘制的命令
- 将该图像呈现在屏幕上,并将其返回到交换链中
这些事件中的每一个都是通过一个函数调用来启动的,但都是异步执行的。函数调用将在操作实际完成之前返回,而且执行的顺序也是未定义的。这是不幸的,因为每一个操作都依赖于前一个操作的完成。因此,我们需要探索我们可以使用哪些基元来实现所需的顺序。
信号量
信号量用于在队列操作之间添加顺序。队列操作是指我们提交给队列的工作,可以是在命令缓冲区中,也可以是在函数中,我们稍后会看到。队列的示例是图形队列和演示队列。信号量用于对同一队列内和不同队列之间的工作进行排序。
Vulkan 中恰好有两种信号量,二进制和时间线。因为本教程将只使用二进制信号量,所以我们不会讨论时间线信号量。进一步提到的术语信号量专门指二进制信号量。
信号量要么是无信号的,要么是有信号的。它以没有信号的方式开始生活。我们使用信号量对队列操作进行排序的方式是在一个队列操作中提供与“信号”信号量相同的信号量,在另一个队列操作中提供与“等待”信号量相同的信号量。例如,假设我们要按顺序执行信号量 S 和队列操作 A 和 B。我们告诉 Vulkan 的是,操作 A 将在完成执行时“发出”信号量 S,而操作 B 将在信号量 S 开始执行之前“等待”它。当操作 A 完成时,信号量 S 将发出信号,而操作 B 在发出 S 信号之前不会开始。操作 B 开始执行后,信号量 S 自动重置为无信号状态,允许再次使用。
刚才描述的伪代码:
VkCommandBuffer A, B = ... // record command buffers
VkSemaphore S = ... // create a semaphore
// enqueue A, signal S when done - starts executing immediately
vkQueueSubmit(work: A, signal: S, wait: None)
// enqueue B, wait on S to start
vkQueueSubmit(work: B, signal: None, wait: S)请注意,在此代码片段中,对 vkQueueSubmit()
的调用都会立即返回 - 等待仅发生在 GPU 上。 CPU
继续运行而不会阻塞。为了让 CPU
等待,我们需要一个不同的同步原语,我们现在将对其进行描述。
栅栏
栅栏具有类似的目的,因为它用于同步执行,但它用于在 CPU 上排序执行,也称为主机。简单地说,如果主机需要知道 GPU 何时完成某事,我们使用栅栏。
与信号量类似,栅栏要么处于有信号状态,要么处于无信号状态。每当我们提交要执行的工作时,我们都可以在该工作上附加一个栅栏。工作完成后,围栏会发出信号。然后我们可以让宿主等待栅栏发出信号,保证在宿主继续之前工作已经完成。
一个具体的例子是截图。假设我们已经在 GPU 上完成了必要的工作。现在需要将图像从 GPU 传输到主机,然后将内存保存到文件中。我们有执行传输的命令缓冲区 A 和围栏 F。我们用围栏 F 提交命令缓冲区 A,然后立即告诉主机等待 F 发出信号。这会导致主机阻塞,直到命令缓冲区 A 完成执行。因此,我们可以安全地让主机将文件保存到磁盘,因为内存传输已经完成。
所描述内容的伪代码:
VkCommandBuffer A = ... // record command buffer with the transfer
VkFence F = ... // create the fence
// enqueue A, start work immediately, signal F when done
vkQueueSubmit(work: A, fence: F)
vkWaitForFence(F) // blocks execution until A has finished executing
save_screenshot_to_disk() // can't run until the transfer has finished与信号量示例不同,此示例 确实 阻止主机执行。这意味着主机不会做任何事情,除非等到执行完成。对于这种情况,我们必须确保传输已完成,然后才能将屏幕截图保存到磁盘。
一般来说,除非必要,否则最好不要阻止主机。我们希望为 GPU 和主机提供有用的工作。等待栅栏发出信号并不是有用的工作。因此,我们更喜欢信号量或其他尚未涵盖的同步原语来同步我们的工作。
必须手动重置栅栏以使其恢复到未发出信号的状态。这是因为栅栏用于控制主机的执行,因此主机可以决定何时重置栅栏。将此与用于在不涉及主机的情况下在 GPU 上订购工作的信号量进行对比。
总之,信号量用于指定 GPU 上操作的执行顺序,而栅栏用于保持 CPU 和 GPU 彼此同步。
选择什么?
我们有两个同步原语可以使用,并且有两个地方可以方便地应用同步:交换链操作和等待前一帧完成。我们希望将信号量用于交换链操作,因为它们发生在 GPU 上,因此如果我们可以提供帮助,我们不想让主机等待。为了等待前一帧完成,我们想使用栅栏,因为我们需要主机等待。这样我们就不会一次绘制超过一帧。因为我们每帧都重新记录命令缓冲区,所以在当前帧完成执行之前,我们不能将下一帧的工作记录到命令缓冲区,因为我们不想在 GPU 使用时覆盖命令缓冲区的当前内容它。
创建同步对象
我们需要一个信号量来表示已从交换链获取图像并准备好渲染,另一个信号量表示渲染已完成并且可以进行演示,还需要一个围栏来确保一次只渲染一帧.
创建三个类成员来存储这些信号量对象和栅栏对象:
VkSemaphore imageAvailableSemaphore;
VkSemaphore renderFinishedSemaphore;
VkFence inFlightFence;为了创建信号量,我们将为教程的这一部分添加最后一个
create 函数:createSyncObjects:
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffer();
createSyncObjects();
}
...
void createSyncObjects() {
}创建信号量需要填写 VkSemaphoreCreateInfo,但在当前版本的
API 中没有除了 sType 之外,实际上还有任何必填字段:
void createSyncObjects() {
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
}Vulkan API 或扩展的未来版本可能会为 flags 和
pNext 参数添加功能,就像它为其他结构所做的那样。
创建栅栏需要填写VkFenceCreateInfo:
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;创建信号量和栅栏遵循熟悉的模式,使用 vkCreateSemaphore
& vkCreateFence:
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphore) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphore) != VK_SUCCESS) ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFence) != VK_SUCCESS){
throw std::runtime_error("failed to create semaphores!");
}信号量和栅栏应该在程序结束时清理,当所有命令都完成并且不再需要同步时:
void cleanup() {
vkDestroySemaphore(device, imageAvailableSemaphore, nullptr);
vkDestroySemaphore(device, renderFinishedSemaphore, nullptr);
vkDestroyFence(device, inFlightFence, nullptr);Onto the main drawing function!
进入主要绘图功能!
等待上一帧
在帧开始时,我们希望等到前一帧结束,以便命令缓冲区和信号量可供使用。为此,我们调用
vkWaitForFences:
void drawFrame() {
vkWaitForFences(device, 1, &inFlightFence, VK_TRUE, UINT64_MAX);
}The vkWaitForFences
function takes an array of fences and waits on the host for either any
or all of the fences to be signaled before returning. The
VK_TRUE we pass here indicates that we want to wait for all
fences, but in the case of a single one it doesn’t matter. This function
also has a timeout parameter that we set to the maximum value of a 64
bit unsigned integer, UINT64_MAX, which effectively
disables the timeout.
After waiting, we need to manually reset the fence to the unsignaled
state with the vkResetFences
call:
vkResetFences(device, 1, &inFlightFence);Before we can proceed, there is a slight hiccup in our design. On the
first frame we call drawFrame(), which immediately waits on
inFlightFence to be signaled. inFlightFence is
only signaled after a frame has finished rendering, yet since this is
the first frame, there are no previous frames in which to signal the
fence! Thus vkWaitForFences() blocks indefinitely, waiting
on something which will never happen.
Of the many solutions to this dilemma, there is a clever workaround
built into the API. Create the fence in the signaled state, so that the
first call to vkWaitForFences() returns immediately since
the fence is already signaled.
To do this, we add the VK_FENCE_CREATE_SIGNALED_BIT flag
to the VkFenceCreateInfo:
void createSyncObjects() {
...
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
...
}从交换链获取图像
我们需要在 drawFrame
函数中做的下一件事是从交换链中获取图像。回想一下,交换链是一个扩展功能,所以我们必须使用具有
vk*KHR 命名约定的函数:
void drawFrame() {
uint32_t imageIndex;
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphore, VK_NULL_HANDLE, &imageIndex);
}vkAcquireNextImageKHR的前两个参数是逻辑设备和交换链,我们希望从中获取一个图像。第三个参数指定了图像可用的超时时间,单位为纳秒。使用一个64位无符号整数的最大值意味着我们有效地禁用了超时。
接下来的两个参数指定了同步对象,当演示引擎使用完图像后,这些对象将被发出信号。这就是我们可以开始对其进行绘制的时间点。可以指定一个信号量、栅栏或两者。在这里我们将使用我们的imageAvailableSemaphore来实现这一目的。
最后一个参数指定了一个变量,用来输出已经变得可用的交换链图像的索引。这个索引指的是我们的swapChainImages数组中的VkImage。我们将使用该索引来选择VkFrameBuffer。
记录命令缓冲区
有了指定要使用的交换链图像的imageIndex,我们现在可以记录命令缓冲区。首先,我们对命令缓冲区调用vkResetCommandBuffer,以确保它能够被记录。
vkResetCommandBuffer(commandBuffer, 0);vkResetCommandBuffer的第二个参数是VkCommandBufferResetFlagBits
标志。由于我们不想做任何特别的事情,所以我们将其保留为 0。
现在调用函数 recordCommandBuffer
来记录我们想要的命令。
recordCommandBuffer(commandBuffer, imageIndex);有了一个完整记录的命令缓冲区,我们现在可以提交了。
提交命令缓冲区
队列提交和同步是通过VkSubmitInfo结构中的参数配置的。
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
VkSemaphore waitSemaphores[] = {imageAvailableSemaphore};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;前三个参数指定了在执行开始前要等待哪些semapho,以及在流水线的哪个(些)阶段等待。我们想等待向图像写入颜色,直到它可用为止,所以我们要指定图形管道中向颜色附件写入的阶段。这意味着理论上,在图像还不可用的时候,实现已经可以开始执行我们的顶点着色器等。waitStages数组中的每个条目都对应于pWaitSemaphores中相同索引的semaphore。
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = commandBuffer;接下来的两个参数指定了哪些命令缓冲区要实际提交执行。我们只需提交我们拥有的单一命令缓冲区。
VkSemaphore signalSemaphores[] = {renderFinishedSemaphore};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;signalSemaphoreCount和pSignalSemaphores参数指定在命令缓冲区执行完毕后向哪些semaphores发出信号。在我们的例子中,我们使用renderFinishedSemaphore来达到这个目的。
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFence) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}现在我们可以使用vkQueueSubmit将命令缓冲区提交给图形队列。该函数以一个VkSubmitInfo结构的数组作为参数,以便在工作负荷大得多时提高效率。最后一个参数引用了一个可选的栅栏,当命令缓冲区执行完毕时,栅栏将被发出信号。这让我们知道什么时候命令缓冲区可以被重新使用是安全的,因此我们要给它inFlightFence。现在在下一帧,CPU将等待这个命令缓冲区执行完毕,然后再把新的命令记录到其中。
子通道依赖项
请记住,渲染通道中的子通道会自动处理图像布局转换。这些转换由子通道依赖控制,它指定子通道之间的内存和执行依赖关系。我们现在只有一个子通道,但是在此子通道之前和之后的操作也算作隐式“子通道”。
有两个内置依赖项负责在渲染通道开始和渲染通道结束时处理过渡,但前者不会在正确的时间发生。它假设过渡发生在管道的开始,但我们还没有在那个时候获取图像!有两种方法可以解决这个问题。我们可以将
imageAvailableSemaphore 的 waitStages 更改为
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT
以确保渲染通道在图像可用之前不会开始,或者我们可以让渲染通道等待
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT
阶段。我决定在这里使用第二个选项,因为这是了解子通道依赖关系及其工作方式的好借口。
子通道依赖项在 VkSubpassDependency
结构中指定。转到createRenderPass函数并添加一个:
VkSubpassDependency dependency{};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;前两个字段指定依赖和依赖子通道的索引。特殊值
VK_SUBPASS_EXTERNAL
指的是渲染通道之前或之后的隐式子通道,具体取决于它是在
srcSubpass 还是 dstSubpass
中指定的。索引“0”指的是我们的子通道,它是第一个也是唯一一个。
dstSubpass 必须始终高于 srcSubpass
以防止依赖图中的循环(除非子通道之一是
VK_SUBPASS_EXTERNAL)。
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;接下来的两个字段指定要等待的操作以及这些操作发生的阶段。我们需要等待交换链完成对图像的读取,然后才能访问它。这可以通过等待颜色附件输出级本身来完成。
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;应该等待的操作是在颜色附件阶段,涉及到颜色附件的写入。这些设置将阻止过渡发生,直到它真正需要(并且允许):当我们想要开始向它写入颜色时。
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;VkRenderPassCreateInfo
结构有两个字段来指定依赖项数组。
展示
绘制一帧的最后一步是将结果提交回交换链,使其最终显示在屏幕上。展示是通过
drawFrame 函数末尾的 VkPresentInfoKHR
结构配置的。
VkPresentInfoKHR presentInfo{};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;前两个参数指定在呈现之前要等待哪些信号量,就像 VkSubmitInfo。由于我们想等待命令缓冲区完成执行,因此我们的三角形被绘制,我们获取将发出信号的信号量并等待它们,因此我们使用signalSemaphores。
VkSwapchainKHR swapChains[] = {swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;接下来的两个参数指定将图像呈现到的交换链以及每个交换链的图像索引。这几乎总是一个。
presentInfo.pResults = nullptr; // Optional最后一个可选参数称为pResults。它允许您指定一组 VkResult
值来检查每个单独的交换链是否显示那是成功的。如果您只使用单个交换链,则没有必要,因为您可以简单地使用当前函数的返回值。
vkQueuePresentKHR(presentQueue, &presentInfo);vkQueuePresentKHR
函数提交请求以向交换链呈现图像。我们将在下一章中为
vkAcquireNextImageKHR 和 vkQueuePresentKHR
添加错误处理,因为它们的失败并不一定意味着程序应该终止,这与我们目前看到的函数不同。
如果到目前为止您所做的一切都是正确的,那么您现在应该在运行程序时看到类似于以下内容的内容:
这个彩色三角形可能看起来与您在图形教程中看到的有点不同。这是因为本教程让着色器在线性颜色空间中进行插值,然后转换为 sRGB 颜色空间。有关差异的讨论,请参阅 this blog post。
耶!不幸的是,您会看到启用验证层后,程序在您关闭时立即崩溃。从
debugCallback 打印到终端的消息告诉我们原因:

请记住,drawFrame中的所有操作都是异步的。这意味着当我们在
mainLoop
中退出循环时,绘图和演示操作可能仍在进行。在这种情况下清理资源是个坏主意。
为了解决这个问题,我们应该在退出 mainLoop
并销毁窗口之前等待逻辑设备完成操作:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
vkDeviceWaitIdle(device);
}您还可以使用 vkQueueWaitIdle
等待特定命令队列中的操作完成。这些函数可以用作执行同步的非常基本的方法。您会看到程序现在在关闭窗口时退出而没有问题。
结论
在 900 多行代码之后,我们终于到了看到屏幕上弹出一些东西的阶段!引导 Vulkan 程序绝对是一项繁重的工作,但要传达的信息是 Vulkan 通过其明确性为您提供了巨大的控制权。我建议您现在花一些时间重新阅读代码,并为程序中所有 Vulkan 对象的用途以及它们之间的关系建立一个心智模型。从现在开始,我们将在这些知识的基础上扩展程序的功能。
下一章将扩展渲染循环以处理飞行中的多个帧。
C++ code / Vertex shader / Fragment shader
运行中的帧
运行中的帧
现在我们的渲染循环有一个明显的缺陷。我们需要等待前一帧完成,然后才能开始渲染下一帧,这会导致主机不必要的空闲。
解决这个问题的方法是允许多个帧同时进行中,也就是说,允许一帧的渲染不干扰下一帧的记录。我们如何做到这一点?在渲染期间访问和修改的任何资源都必须复制。因此,我们需要多个命令缓冲区、信号量和栅栏。在后面的章节中,我们还将添加其他资源的多个实例,因此我们将看到这个概念再次出现。
首先在程序顶部添加一个常量,该常量定义应同时处理的帧数:
const int MAX_FRAMES_IN_FLIGHT = 2;我们选择数字 2 是因为我们不希望 CPU 远远领先于 GPU。有 2 帧在飞行中,CPU 和 GPU 可以同时处理它们自己的任务。如果 CPU 提前完成,它将等到 GPU 完成渲染后再提交更多工作。如果有 3 帧或更多帧在运行,CPU 可能会领先于 GPU,从而增加帧延迟。通常,不需要额外的延迟。但是让应用程序控制飞行中的帧数是 Vulkan 显式的另一个例子。
每个帧都应该有自己的命令缓冲区、信号量集和栅栏。重命名然后将它们更改为对象的std::vectors:
std::vector<VkCommandBuffer> commandBuffers;
...
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
std::vector<VkFence> inFlightFences;然后我们需要创建多个命令缓冲区。将“createCommandBuffer”重命名为“createCommandBuffers”。接下来我们需要将命令缓冲区向量的大小调整为
MAX_FRAMES_IN_FLIGHT 的大小,更改 VkCommandBufferAllocateInfo
来包含这么多命令缓冲区,然后将目标更改为我们的命令缓冲区向量:
void createCommandBuffers() {
commandBuffers.resize(MAX_FRAMES_IN_FLIGHT);
...
allocInfo.commandBufferCount = (uint32_t) commandBuffers.size();
if (vkAllocateCommandBuffers(device, &allocInfo, commandBuffers.data()) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate command buffers!");
}
}应更改 createSyncObjects 函数以创建所有对象:
void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create synchronization objects for a frame!");
}
}
}同样,它们也应该全部清理:
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
...
}请记住,因为当我们释放命令池时,命令缓冲区已为我们释放,所以命令缓冲区清理无需额外操作。
要在每一帧都使用正确的对象,我们需要跟踪当前帧。为此,我们将使用帧索引:
uint32_t currentFrame = 0;drawFrame 函数现在可以修改为使用正确的对象:
void drawFrame() {
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
vkResetFences(device, 1, &inFlightFences[currentFrame]);
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
...
vkResetCommandBuffer(commandBuffers[currentFrame], 0);
recordCommandBuffer(commandBuffers[currentFrame], imageIndex);
...
submitInfo.pCommandBuffers = &commandBuffers[currentFrame];
...
VkSemaphore waitSemaphores[] = {imageAvailableSemaphores[currentFrame]};
...
VkSemaphore signalSemaphores[] = {renderFinishedSemaphores[currentFrame]};
...
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
}当然,我们不应该忘记每次都前进到下一帧:
void drawFrame() {
...
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;
}通过使用模 (%) 运算符,我们确保帧索引在每个
MAX_FRAMES_IN_FLIGHT 入队帧之后循环。
我们现在已经实现了所有需要的同步,以确保入队的工作帧不超过
MAX_FRAMES_IN_FLIGHT
帧,并且这些帧不会相互重叠。请注意,对于代码的其他部分(例如最终清理),可以依赖更粗略的同步,例如
vkDeviceWaitIdle。您应该根据性能要求决定使用哪种方法。
要通过示例了解有关同步的更多信息,请查看 Khronos 的 此广泛概述 .
在下一章中,我们将处理一个表现良好的 Vulkan 程序所需的另一件小事。
C++ code / Vertex shader / Fragment shader
重新创建交换链
介绍
我们现在的应用程序成功地绘制了一个三角形,但是在某些情况下它还没有正确处理。窗口表面可能会发生变化,从而使交换链不再与它兼容。可能导致这种情况发生的原因之一是窗口大小的变化。我们必须捕捉这些事件并重新创建交换链。
重新创建交换链
创建一个新的 recreateSwapChain 函数,该函数调用
createSwapChain
以及依赖于交换链或窗口大小的对象的所有创建函数。
void recreateSwapChain() {
vkDeviceWaitIdle(device);
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}我们首先调用 vkDeviceWaitIdle,因为就像上一章一样,我们不应该接触资源可能仍在使用中。显然,我们要做的第一件事就是重新创建交换链本身。图像视图需要重新创建,因为它们直接基于交换链图像。渲染通道需要重新创建,因为它取决于交换链图像的格式。在窗口调整大小等操作期间,交换链图像格式很少发生变化,但仍应进行处理。视口和剪刀矩形大小是在创建图形管线时指定的,因此管线也需要重建。可以通过对视口和剪刀矩形使用动态状态来避免这种情况。最后,帧缓冲区直接依赖于交换链图像。
为了确保这些对象的旧版本在重新创建它们之前被清理,我们应该将一些清理代码移动到一个单独的函数中,我们可以从
recreateSwapChain
函数调用该函数。让我们称之为cleanupSwapChain:
void cleanupSwapChain() {
}
void recreateSwapChain() {
vkDeviceWaitIdle(device);
cleanupSwapChain();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}我们将作为交换链刷新的一部分重新创建的所有对象的清理代码从cleanup移动到cleanupSwapChain:
void cleanupSwapChain() {
for (size_t i = 0; i < swapChainFramebuffers.size(); i++) {
vkDestroyFramebuffer(device, swapChainFramebuffers[i], nullptr);
}
vkDestroyPipeline(device, graphicsPipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
vkDestroyRenderPass(device, renderPass, nullptr);
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
vkDestroyImageView(device, swapChainImageViews[i], nullptr);
}
vkDestroySwapchainKHR(device, swapChain, nullptr);
}
void cleanup() {
cleanupSwapChain();
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
vkDestroyCommandPool(device, commandPool, nullptr);
vkDestroyDevice(device, nullptr);
if (enableValidationLayers) {
DestroyDebugUtilsMessengerEXT(instance, debugMessenger, nullptr);
}
vkDestroySurfaceKHR(instance, surface, nullptr);
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}请注意,在 chooseSwapExtent
中,我们已经查询了新窗口分辨率以确保交换链图像具有(新的)正确大小,因此无需修改
chooseSwapExtent(请记住,我们已经使用
glfwGetFramebufferSize
获取创建交换链时表面的分辨率(以像素为单位)。
这就是重新创建交换链所需的全部内容!但是,这种方法的缺点是我们需要在创建新的交换链之前停止所有渲染。可以在来自旧交换链的图像上的绘图命令仍在进行中时创建新的交换链。您需要将先前的交换链传递给
VkSwapchainCreateInfoKHR 结构中的 oldSwapChain
字段,并在使用完旧的交换链后立即销毁它。
不匹配或者过时的交换链
现在我们只需要确定何时需要重新创建交换链并调用我们的新
recreateSwapChain 函数。幸运的是,Vulkan
通常只会告诉我们交换链在演示过程中已经不够用了。
vkAcquireNextImageKHR 和 vkQueuePresentKHR
函数可以返回以下特殊值来表明这一点。
VK_ERROR_OUT_OF_DATE_KHR:交换链与表面不兼容,不能再用于渲染。通常发生在窗口调整大小之后。VK_SUBOPTIMAL_KHR:交换链仍可用于成功呈现到表面,但表面属性不再完全匹配。
VkResult result = vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
if (result == VK_ERROR_OUT_OF_DATE_KHR) {
recreateSwapChain();
return;
} else if (result != VK_SUCCESS && result != VK_SUBOPTIMAL_KHR) {
throw std::runtime_error("failed to acquire swap chain image!");
}如果在尝试获取图像时交换链已过期,则无法再向其呈现。因此,我们应该立即重新创建交换链并在下一次
drawFrame 调用中重试。
如果交换链不是最理想的,您也可以决定这样做,但我选择在这种情况下继续进行,因为我们已经获取了图像。
VK_SUCCESS 和 VK_SUBOPTIMAL_KHR
都被认为是“成功”返回码。
result = vkQueuePresentKHR(presentQueue, &presentInfo);
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR) {
recreateSwapChain();
} else if (result != VK_SUCCESS) {
throw std::runtime_error("failed to present swap chain image!");
}
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;vkQueuePresentKHR
函数返回具有相同含义的相同值。在这种情况下,如果交换链不是最理想的,我们也会重新创建它,因为我们想要最好的结果。
修复死锁
如果我们现在尝试运行代码,可能会遇到死锁。调试代码,我们发现应用程序到达
vkWaitForFences
但从未继续通过它。这是因为当 vkAcquireNextImageKHR 返回
VK_ERROR_OUT_OF_DATE_KHR 时,我们重新创建了交换链,然后从
drawFrame
返回。但在此之前,当前帧的栅栏被等待并重置。由于我们立即返回,因此没有提交任何工作执行,并且永远不会发出围栏信号,导致
vkWaitForFences
永远停止。
谢天谢地,有一个简单的解决方法。延迟重置围栏,直到我们确定我们将提交使用它的工作。因此,如果我们提前返回,围栏仍然会发出信号,并且
vkWaitForFences
下次不会死锁我们使用相同的栅栏对象。
drawFrame 的开头现在应该如下所示:
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
uint32_t imageIndex;
VkResult result = vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
if (result == VK_ERROR_OUT_OF_DATE_KHR) {
recreateSwapChain();
return;
} else if (result != VK_SUCCESS && result != VK_SUBOPTIMAL_KHR) {
throw std::runtime_error("failed to acquire swap chain image!");
}
// Only reset the fence if we are submitting work
vkResetFences(device, 1, &inFlightFences[currentFrame]);显式处理调整大小
尽管许多驱动程序和平台在调整窗口大小后会自动触发VK_ERROR_OUT_OF_DATE_KHR,但并不保证一定会发生。这就是为什么我们将添加一些额外的代码来显式地处理调整大小。首先添加一个新的成员变量来标记发生了调整大小:
std::vector<VkFence> inFlightFences;
bool framebufferResized = false;然后应该修改 drawFrame 函数以检查此标志:
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR || framebufferResized) {
framebufferResized = false;
recreateSwapChain();
} else if (result != VK_SUCCESS) {
...
}在 vkQueuePresentKHR
之后执行此操作很重要,以确保信号量处于一致状态,否则可能永远无法正确等待已发出信号量。现在要实际检测调整大小,我们可以使用
GLFW 框架中的 glfwSetFramebufferSizeCallback
函数来设置回调:
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);
}
static void framebufferResizeCallback(GLFWwindow* window, int width, int height) {
}我们创建 static 函数作为回调的原因是因为 GLFW
不知道如何使用正确的 this
指针正确调用成员函数,该指针指向我们的
HelloTriangleApplication 实例。
但是,我们确实在回调中获得了对GLFWwindow的引用,并且还有另一个
GLFW
函数允许您在其中存储任意指针:glfwSetWindowUserPointer:
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetWindowUserPointer(window, this);
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);现在可以使用 glfwGetWindowUserPointer
从回调中检索此值,以正确设置标志:
static void framebufferResizeCallback(GLFWwindow* window, int width, int height) {
auto app = reinterpret_cast<HelloTriangleApplication*>(glfwGetWindowUserPointer(window));
app->framebufferResized = true;
}现在尝试运行程序并调整窗口大小,以查看帧缓冲区是否确实与窗口正确调整大小。
处理最小化
还有另一种情况,交换链可能会过时,这是一种特殊的窗口大小调整:窗口最小化。这种情况很特殊,因为它会导致帧缓冲区大小为“0”。在本教程中,我们将通过扩展
recreateSwapChain
函数暂停直到窗口再次位于前台来处理这个问题:
void recreateSwapChain() {
int width = 0, height = 0;
glfwGetFramebufferSize(window, &width, &height);
while (width == 0 || height == 0) {
glfwGetFramebufferSize(window, &width, &height);
glfwWaitEvents();
}
vkDeviceWaitIdle(device);
...
}对 glfwGetFramebufferSize 的初始调用会处理大小已经正确且
glfwWaitEvents 没有任何等待的情况。
恭喜,您现在已经完成了您的第一个表现良好的 Vulkan 程序!在下一章中,我们将摆脱顶点着色器中的硬编码顶点,并实际使用顶点缓冲区。
留言板