本文档是对Vulkan Tutorial教程的翻译,非官方翻译,仅供vulkan爱好者参考学习。如果有翻译错误,请留言指出,或者联系占航(hangliebe@163.com)进行修正,感谢。建议英文好的朋友直接读原文档。
关注我的微博主页
2022-02-20 v1.0
Uniform缓冲区
描述符布局和缓冲区简介
我们现在能够为每个顶点向顶点着色器传递任意的属性,但全局变量呢?从这一章开始,我们将转向3D图形,这需要一个模型-视图-投影矩阵。我们可以把它作为顶点数据,但这是对内存的浪费,而且每当变换发生变化时,我们都需要更新顶点缓冲器。变换可能很容易在每一帧都发生变化。
在Vulkan中解决这个问题的正确方法是使用资源描述符。描述符是一种让着色器自由访问缓冲区和图像等资源的方式。我们将设置一个包含变换矩阵的缓冲区,让顶点着色器通过描述符来访问它们。描述符的使用由三部分组成。
- 在流水线创建过程中指定一个描述符布局
- 从描述符池中分配一个描述符集
- 在渲染过程中绑定描述符集
描述符布局指定了将被管道访问的资源类型,就像渲染通道指定了将被访问的附件的类型。描述符集指定实际的缓冲区或图像资源将被绑定到描述符上,就像帧缓冲区指定实际的图像视图来绑定到渲染通道附件上一样。然后,描述符集就像顶点缓冲区和帧缓冲区一样被绑定到绘图命令中。
有许多类型的描述符,但在本章中我们将使用统一缓冲区对象(UBO)。我们将在以后的章节中研究其他类型的描述符,但基本过程是一样的。假设我们在一个C结构中拥有我们希望顶点着色器拥有的数据,就像这样:
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};然后我们可以将数据复制到一个VkBuffer,并通过统一的缓冲区对象描述符从顶点着色器中访问它,像这样:
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}我们要在每一帧更新模型、视图和投影矩阵,使前一章的矩形在三维中旋转。
顶点着色器
修改顶点着色器,使其包括上面指定的统一缓冲器对象。我将假设你对MVP变换很熟悉。如果你不熟悉,请参阅第一章中提到的资源。
#version 450
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;
layout(location = 0) in vec2 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}注意uniform、in和out声明的顺序并不重要。绑定
“指令类似于属性的”location
“指令。我们要在描述符布局中引用这个绑定。带有gl_Position的一行被改变为使用变换来计算剪辑坐标的最终位置。与二维三角形不同,剪辑坐标的最后一个分量可能不是`1’,这将导致在转换为屏幕上最终的归一化设备坐标时出现分割。这在透视投影中被用作透视分割,对于使较近的物体看起来比较远的物体大是至关重要的。
描述符集布局
下一步是在C++端定义UBO,并在顶点着色器中告诉Vulkan这个描述符。
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};我们可以使用GLM中的数据类型完全匹配着色器中的定义。矩阵中的数据与着色器期望的方式是二进制兼容的,所以我们以后可以直接memcpy一个UniformBufferObject到一个VkBuffer。
我们需要提供在着色器中用于管道创建的每个描述符绑定的细节,就像我们必须为每个顶点属性及其location索引做的那样。我们将设置一个新的函数来定义所有这些信息,称为createDescriptorSetLayout。它应该在管道创建之前被调用,因为我们将在那里需要它。
void initVulkan() {
...
createDescriptorSetLayout();
createGraphicsPipeline();
...
}
...
void createDescriptorSetLayout() {
}每个绑定需要通过一个VkDescriptorSetLayoutBinding结构来描述。
void createDescriptorSetLayout() {
VkDescriptorSetLayoutBinding uboLayoutBinding{};
uboLayoutBinding.binding = 0;
uboLayoutBinding.descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
uboLayoutBinding.descriptorCount = 1;
}前两个字段指定了着色器中使用的
binding和描述符的类型,是一个统一的缓冲区对象。着色器变量有可能代表一个统一缓冲区对象的数组,descriptorCount指定数组中的数值数量。例如,这可以用来为骨骼动画中的每根骨头指定一个变换。我们的MVP转换是在一个统一的缓冲区对象中,所以我们使用descriptorCount为1。
uboLayoutBinding.stageFlags = VK_SHADER_STAGE_VERTEX_BIT;我们还需要指定描述符将在哪个着色器阶段被引用。stageFlags字段可以是VkShaderStageFlagBits值或VK_SHADER_STAGE_ALL_GRAPHICS值的组合。在我们的例子中,我们只引用了顶点着色器的描述符。
uboLayoutBinding.pImmutableSamplers = nullptr; // OptionalpImmutableSamplers字段只与图像采样相关的描述符有关,我们将在后面看。你可以将其保留为默认值。
所有的描述符绑定被组合成一个VkDescriptorSetLayout对象。在`pipelineLayout’上面定义一个新的类成员。
VkDescriptorSetLayout descriptorSetLayout;
VkPipelineLayout pipelineLayout;然后我们可以使用vkCreateDescriptorSetLayout创建它。这个函数接受一个简单的VkDescriptorSetLayoutCreateInfo与绑定的数组:
VkDescriptorSetLayoutCreateInfo layoutInfo{};
layoutInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO;
layoutInfo.bindingCount = 1;
layoutInfo.pBindings = &uboLayoutBinding;
if (vkCreateDescriptorSetLayout(device, &layoutInfo, nullptr, &descriptorSetLayout) != VK_SUCCESS) {
throw std::runtime_error("failed to create descriptor set layout!");
}我们需要在管道创建过程中指定描述符集布局,以告诉Vulkan着色器将使用哪些描述符。描述符集的布局是在管道布局对象中指定的。修改VkPipelineLayoutCreateInfo以引用布局对象。
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 1;
pipelineLayoutInfo.pSetLayouts = &descriptorSetLayout;你可能想知道为什么在这里可以指定多个描述符集布局,因为一个单一的描述符集已经包括了所有的绑定。我们将在下一章中回到这个问题,在那里我们将研究描述符池和描述符集。
在我们可能创建新的图形管道时,描述符布局应该坚持下去,也就是说,直到程序结束:
void cleanup() {
cleanupSwapChain();
vkDestroyDescriptorSetLayout(device, descriptorSetLayout, nullptr);
...
}Uniform缓冲区
在下一章中,我们将为着色器指定包含UBO数据的缓冲区,但我们需要先创建这个缓冲区。我们将在每一帧复制新的数据到统一的缓冲区,所以有一个暂存的缓冲区并没有什么意义。在这种情况下,它只会增加额外的开销,而且很可能降低性能而不是提高性能。
我们应该有多个缓冲区,因为多个帧可能同时在飞行,我们不想在前一帧还在读的时候更新缓冲区,为下一帧做准备。因此,我们需要有多少个统一的缓冲区,就有多少个飞行中的帧,并向当前没有被GPU读取的统一缓冲区写入。
为此,为uniformBuffers和uniformBuffersMemory添加新的类成员:
VkBuffer indexBuffer;
VkDeviceMemory indexBufferMemory;
std::vector<VkBuffer> uniformBuffers;
std::vector<VkDeviceMemory> uniformBuffersMemory;同样,创建一个新的函数createUniformBuffers,在createIndexBuffer之后调用,分配缓冲区:
void initVulkan() {
...
createVertexBuffer();
createIndexBuffer();
createUniformBuffers();
...
}
...
void createUniformBuffers() {
VkDeviceSize bufferSize = sizeof(UniformBufferObject);
uniformBuffers.resize(MAX_FRAMES_IN_FLIGHT);
uniformBuffersMemory.resize(MAX_FRAMES_IN_FLIGHT);
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
createBuffer(bufferSize, VK_BUFFER_USAGE_UNIFORM_BUFFER_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, uniformBuffers[i], uniformBuffersMemory[i]);
}
}我们要写一个单独的函数,用每一帧新的变换来更新统一缓冲区,所以这里将没有vkMapMemory。统一数据将被用于所有的绘制调用,所以包含它的缓冲区应该只在我们停止渲染时被销毁。由于它还取决于交换链图像的数量,而这可能在重新创建后发生变化,我们将在cleanupSwapChain中清理它:
void cleanupSwapChain() {
...
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroyBuffer(device, uniformBuffers[i], nullptr);
vkFreeMemory(device, uniformBuffersMemory[i], nullptr);
}
}这意味着我们还需要在recreateSwapChain中重新创建它:
void recreateSwapChain() {
...
createFramebuffers();
createUniformBuffers();
createCommandBuffers();
}更新uniform 数据
创建一个新的函数updateUniformBuffer,并在我们知道要获取哪个交换链图像之后,从drawFrame函数中添加一个对它的调用:
void drawFrame() {
...
uint32_t imageIndex;
VkResult result = vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
...
updateUniformBuffer(imageIndex);
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
...
}
...
void updateUniformBuffer(uint32_t currentImage) {
}这个函数将在每一帧生成一个新的变换,以使几何体旋转起来。我们需要包括两个新的头文件来实现这个功能:
#define GLM_FORCE_RADIANS
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <chrono>glm/gtc/matrix_transform.hpp头暴露了可用于生成模型变换的函数,如glm::rotate,视图变换如glm::lookAt和投影变换如glm::perspective。GLM_FORCE_RADIANS定义是必要的,以确保像glm::rotate这样的函数使用弧度作为参数,以避免任何可能的混淆。
chrono标准库头暴露了做精确计时的函数。我们将使用它来确保几何体每秒钟旋转90度,而不考虑帧速率。
void updateUniformBuffer(uint32_t currentImage) {
static auto startTime = std::chrono::high_resolution_clock::now();
auto currentTime = std::chrono::high_resolution_clock::now();
float time = std::chrono::duration<float, std::chrono::seconds::period>(currentTime - startTime).count();
}updateUniformBuffer函数一开始会用一些逻辑来计算从浮点精度的渲染开始以来的时间(秒)。
现在我们将在统一缓冲区对象中定义模型、视图和投影的变换。模型的旋转将是一个简单的围绕Z轴的旋转,使用time变量:
UniformBufferObject ubo{};
ubo.model = glm::rotate(glm::mat4(1.0f), time * glm::radians(90.0f), glm::vec3(0.0f, 0.0f, 1.0f));glm::rotate函数接受一个现有的变换、旋转角度和旋转轴作为参数。glm::mat4(1.0f)构造函数返回一个身份矩阵。使用time * glm::radians(90.0f)的旋转角度可以达到每秒旋转90度的目的。
ubo.view = glm::lookAt(glm::vec3(2.0f, 2.0f, 2.0f), glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3(0.0f, 0.0f, 1.0f));对于视图转换,我决定从上方以45度角观察几何体。glm::lookAt函数将眼睛位置、中心位置和上轴作为参数。
ubo.proj = glm::perspective(glm::radians(45.0f), swapChainExtent.width / (float) swapChainExtent.height, 0.1f, 10.0f);我选择了使用45度垂直视场的透视投影。其他参数是长宽比、近景和远景平面。重要的是使用当前的交换链范围来计算长宽比,以考虑到调整大小后窗口的新宽度和高度。
ubo.proj[1][1] *= -1;GLM最初是为OpenGL设计的,其中剪辑坐标的Y坐标是倒置的。最简单的补偿方法是在投影矩阵中翻转Y轴的缩放系数的符号。如果你不这样做,那么图像就会被倒过来渲染。
现在所有的变换都被定义了,所以我们可以将统一缓冲区对象中的数据复制到当前的统一缓冲区中。这与我们对顶点缓冲区的处理方式完全相同,只是没有分流缓冲区:
void* data;
vkMapMemory(device, uniformBuffersMemory[currentImage], 0, sizeof(ubo), 0, &data);
memcpy(data, &ubo, sizeof(ubo));
vkUnmapMemory(device, uniformBuffersMemory[currentImage]);以这种方式使用UBO并不是向着色器传递频繁变化的数值的最有效方式。一个更有效的方法是将一个小的数据缓冲区传递给着色器,这就是push constants。我们可以在未来的一章中研究这些。
在下一章中,我们将研究描述符集,它实际上将把VkBuffer绑定到统一的缓冲区描述符上,以便着色器能够访问这些转换数据。
C++ code / Vertex shader / Fragment shader
描述符池和描述符集
简介
上一章的描述符布局描述了可以绑定的描述符的类型。在本章中,我们要为每个VkBuffer资源创建一个描述符集,将其与统一缓冲区描述符绑定。
描述符池
描述符集不能直接创建,它们必须像命令缓冲区一样从一个池中分配。描述符集的等价物不出所料地被称为描述符池。我们将写一个新的函数createDescriptorPool来设置它。
void initVulkan() {
...
createUniformBuffers();
createDescriptorPool();
...
}
...
void createDescriptorPool() {
}我们首先需要使用VkDescriptorPoolSize结构来描述我们的描述符集将包含哪些描述符类型以及它们的数量。
VkDescriptorPoolSize poolSize{};
poolSize.type = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
poolSize.descriptorCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);我们首先需要使用VkDescriptorPoolSize结构来描述我们的描述符集将包含哪些描述符类型以及它们的数量:
VkDescriptorPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO;
poolInfo.poolSizeCount = 1;
poolInfo.pPoolSizes = &poolSize;除了可用的单个描述符的最大数量外,我们还需要指定可能被分配的描述符集的最大数量:
poolInfo.maxSets = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);该结构有一个类似于命令池的可选标志,决定单个描述符集是否可以被释放:VK_DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET_BIT。我们在创建描述符集后不打算碰它,所以我们不需要这个标志。你可以让flags保持其默认值0。
VkDescriptorPool descriptorPool;
...
if (vkCreateDescriptorPool(device, &poolInfo, nullptr, &descriptorPool) != VK_SUCCESS) {
throw std::runtime_error("failed to create descriptor pool!");
}添加一个新的类成员来存储描述符池的句柄,并调用vkCreateDescriptorPool
来创建它。
描述符集
我们现在可以分配描述符集本身。为此添加一个createDescriptorSets函数:
void initVulkan() {
...
createDescriptorPool();
createDescriptorSets();
...
}
void recreateSwapChain() {
...
createDescriptorPool();
createDescriptorSets();
...
}
...
void createDescriptorSets() {
}描述符集分配是用VkDescriptorSetAllocateInfo结构描述的。你需要指定要分配的描述符池,要分配的描述符集的数量,以及要基于的描述符布局:
std::vector<VkDescriptorSetLayout> layouts(MAX_FRAMES_IN_FLIGHT, descriptorSetLayout);
VkDescriptorSetAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO;
allocInfo.descriptorPool = descriptorPool;
allocInfo.descriptorSetCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
allocInfo.pSetLayouts = layouts.data();在我们的例子中,我们将为每个交换链图像创建一个描述符集,所有的描述符集都具有相同的布局。不幸的是,我们确实需要所有的布局副本,因为下一个函数希望有一个与描述符集数量相匹配的数组。
添加一个类成员来保存描述符集句柄,用vkAllocateDescriptorSets来分配它们:
VkDescriptorPool descriptorPool;
std::vector<VkDescriptorSet> descriptorSets;
...
descriptorSets.resize(MAX_FRAMES_IN_FLIGHT);
if (vkAllocateDescriptorSets(device, &allocInfo, descriptorSets.data()) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate descriptor sets!");
}你不需要明确地清理描述符集,因为当描述符池被销毁时,它们将被自动释放。对vkAllocateDescriptorSets的调用将分配描述符集,每个描述符集有一个统一的缓冲区描述符。
void cleanup() {
...
vkDestroyDescriptorPool(device, descriptorPool, nullptr);
vkDestroyDescriptorSetLayout(device, descriptorSetLayout, nullptr);
...
}现在描述符集已经被分配了,但是里面的描述符仍然需要被配置。我们现在要添加一个循环来填充每个描述符:
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
}引用缓冲区的描述符,如我们的统一缓冲区描述符,是用VkDescriptorBufferInfo结构配置的。这个结构指定了缓冲区和其中包含描述符数据的区域。
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
VkDescriptorBufferInfo bufferInfo{};
bufferInfo.buffer = uniformBuffers[i];
bufferInfo.offset = 0;
bufferInfo.range = sizeof(UniformBufferObject);
}如果你要覆盖整个缓冲区,就像我们在这个例子中一样,那么也可以使用VK_WHOLE_SIZE值作为范围。描述符的配置是通过vkUpdateDescriptorSets函数更新的,该函数以VkWriteDescriptorSet结构的数组作为参数。
VkWriteDescriptorSet descriptorWrite{};
descriptorWrite.sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descriptorWrite.dstSet = descriptorSets[i];
descriptorWrite.dstBinding = 0;
descriptorWrite.dstArrayElement = 0;前两个字段指定要更新的描述符集和绑定。我们给我们的统一缓冲区绑定索引0。记住,描述符可以是数组,所以我们还需要指定我们要更新的数组中的第一个索引。我们没有使用数组,所以索引是简单的0。
descriptorWrite.descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
descriptorWrite.descriptorCount = 1;我们需要再次指定描述符的类型。可以在一个数组中一次更新多个描述符,从索引dstArrayElement开始。descriptorCount字段指定你要更新多少个数组元素。
descriptorWrite.pBufferInfo = &bufferInfo;
descriptorWrite.pImageInfo = nullptr; // Optional
descriptorWrite.pTexelBufferView = nullptr; // Optional最后一个字段引用了一个包含descriptorCount结构的数组,这些结构实际上配置了描述符。这取决于描述符的类型,你实际上需要使用这三个中的哪一个。pBufferInfo字段用于引用缓冲区数据的描述符,pImageInfo用于引用图像数据的描述符,而pTexelBufferView用于引用缓冲区视图的描述符。我们的描述符是基于缓冲区的,所以我们使用pBufferInfo。
vkUpdateDescriptorSets(device, 1, &descriptorWrite, 0, nullptr);更新是使用vkUpdateDescriptorSets进行的。它接受两种数组作为参数:一个VkWriteDescriptorSet的数组和一个VkCopyDescriptorSet的数组。后者可以用来互相复制描述符,正如它的名字所暗示的。
使用描述符集
我们现在需要更新 “createCommandBuffers”函数,用vkCmdBindDescriptorSets将每个交换链图像的正确描述符集实际绑定到着色器中的描述符。这需要在调用vkCmdDrawIndexed之前完成:
vkCmdBindDescriptorSets(commandBuffers[i], VK_PIPELINE_BIND_POINT_GRAPHICS, pipelineLayout, 0, 1, &descriptorSets[i], 0, nullptr);
vkCmdDrawIndexed(commandBuffers[i], static_cast<uint32_t>(indices.size()), 1, 0, 0, 0);与顶点和索引缓冲区不同,描述符集对图形管道来说并不唯一。因此,我们需要指定我们是否要将描述符集绑定到图形或计算管道上。下一个参数是描述符所基于的布局。接下来的三个参数指定了第一个描述符集的索引,要绑定的描述符集的数量,以及要绑定的描述符集的阵列。我们稍后会回到这个问题上。最后两个参数指定了一个用于动态描述符的偏移量数组。我们将在以后的章节中研究这些。
如果你现在运行你的程序,那么你会注意到,不幸的是,什么都看不到。问题是,由于我们在投影矩阵中做了Y翻转,顶点现在是以逆时针顺序而不是顺时针顺序被绘制的。这导致了背面剔除的发生,并阻止了任何几何图形的绘制。转到createGraphicsPipeline函数,修改VkPipelineRasterizationStateCreateInfo中的frontFace以纠正这个问题:
rasterizer.cullMode = VK_CULL_MODE_BACK_BIT;
rasterizer.frontFace = VK_FRONT_FACE_COUNTER_CLOCKWISE;再次运行你的程序,你现在应该看到以下内容。
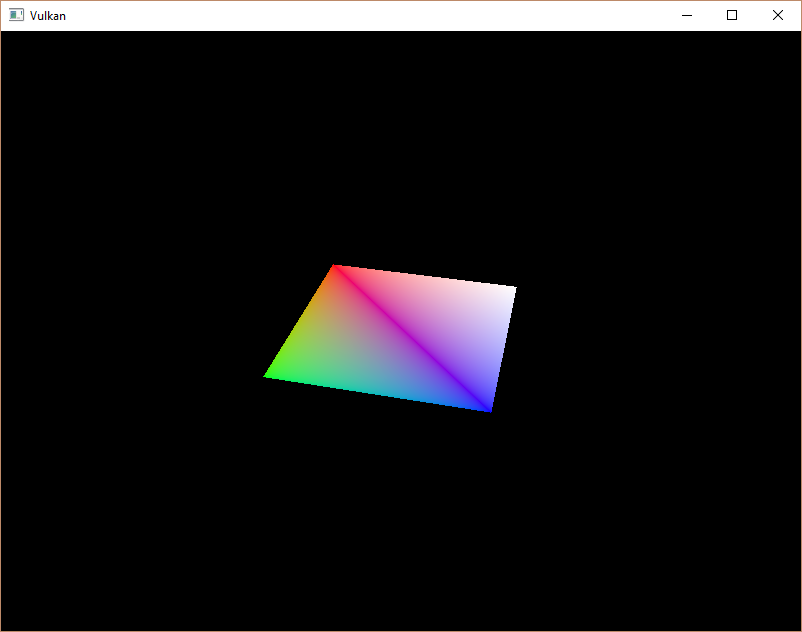
矩形已经变成了正方形,因为投影矩阵现在纠正了长宽比。updateUniformBuffer处理了屏幕大小的调整,所以我们不需要重新创建recreateSwapChain中设置的描述符。
对齐要求
到目前为止,我们已经忽略了一件事,那就是C++结构中的数据到底应该如何与着色器中的统一定义相匹配。简单地在两者中使用相同的类型似乎已经很明显了:
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;然而,这并不是它的全部内容。例如,尝试修改结构和着色器,使其看起来像这样:
struct UniformBufferObject {
glm::vec2 foo;
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
layout(binding = 0) uniform UniformBufferObject {
vec2 foo;
mat4 model;
mat4 view;
mat4 proj;
} ubo;重新编译你的着色器和你的程序并运行它,你会发现到目前为止你所做的彩色方块已经消失了!为什么?这是因为我们没有考虑到对齐的要求。
例如,Vulkan希望你的结构中的数据在内存中以一种特定的方式对齐。
- 标量必须按N(=4字节,给定32位浮点)对齐。
- 一个
vec2必须按2N(=8字节)对齐。 - 一个
vec3'或vec4’必须按4N(=16字节)对齐。 - 一个嵌套结构必须以其成员的基本对齐方式对齐,并四舍五入到16的倍数。
- 一个
mat4矩阵必须与vec4的对齐方式相同。
你可以在the specification中找到完整的对齐要求列表。
我们最初的着色器只有三个mat4字段,已经满足了对齐要求。由于每个mat4的大小为4
x 4 x 4 =
64字节,model的偏移量为0,view的偏移量为64,proj的偏移量为128。所有这些都是16的倍数,这就是为什么它运行良好。
新的结构以vec2开始,它只有8个字节大小,因此抛开了所有的偏移量。现在model的偏移量是8,view的偏移量是72,proj的偏移量是136,这些都不是16的倍数。为了解决这个问题,我们可以使用C++11中引入的alignas指定器:
struct UniformBufferObject {
glm::vec2 foo;
alignas(16) glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};如果你现在再次编译并运行你的程序,你应该看到着色器再次正确地接收其矩阵值。
幸运的是,有一种方法可以让我们在大多数时候不必考虑这些对齐要求。我们可以在包含GLM之前定义GLM_FORCE_DEFAULT_ALIGNED_GENTYPES:
#define GLM_FORCE_RADIANS
#define GLM_FORCE_DEFAULT_ALIGNED_GENTYPES
#include <glm/glm.hpp>这将迫使GLM使用vec2和mat4的一个版本,该版本已经为我们指定了对齐要求。如果你添加了这个定义,那么你可以删除alignas指定符,你的程序应该仍然可以工作。
不幸的是,如果你开始使用嵌套结构,这种方法就会失效。考虑一下C++代码中的以下定义:
struct Foo {
glm::vec2 v;
};
struct UniformBufferObject {
Foo f1;
Foo f2;
};还有下面的着色器定义:
struct Foo {
vec2 v;
};
layout(binding = 0) uniform UniformBufferObject {
Foo f1;
Foo f2;
} ubo;在这种情况下,f2的偏移量为8,而它的偏移量应该是16,因为它是一个嵌套结构。在这种情况下,你必须自己指定对齐方式。
struct UniformBufferObject {
Foo f1;
alignas(16) Foo f2;
};这些问题是一个很好的理由,要始终明确对齐的问题。这样,你就不会被对齐错误的奇怪异常所吓倒。
struct UniformBufferObject {
alignas(16) glm::mat4 model;
alignas(16) glm::mat4 view;
alignas(16) glm::mat4 proj;
};不要忘记在删除foo字段后重新编译你的着色器。
多个描述符集
正如一些结构和函数调用所暗示的,实际上是可以同时绑定多个描述符集的。你需要在创建管道布局时为每个描述符集指定一个描述符布局。然后,着色器可以像这样引用特定的描述符集。
layout(set = 0, binding = 0) uniform UniformBufferObject { ... }你可以使用这个功能,将每个对象不同的描述符和共享的描述符放入单独的描述符集。在这种情况下,你可以避免在不同的绘制调用中重新绑定大部分描述符,这可能会更有效率。
留言板